核心内容:
- 使用 n8n 和 rsshub 监控公众号文章。
- 通过搜狗的微信搜索和模拟浏览器请求头绕过反爬虫机制。
- 提取文章标题、作者、发布时间和正文内容,并可将数据存入向量数据库或进行其他自动化处理。
源自 | kayin9凯隐的无人化生产矩阵 2025-06-14 15:48
53天前,微信公众号 AI 赛道的顶流卡兹克做了个监控奥特曼的文章。
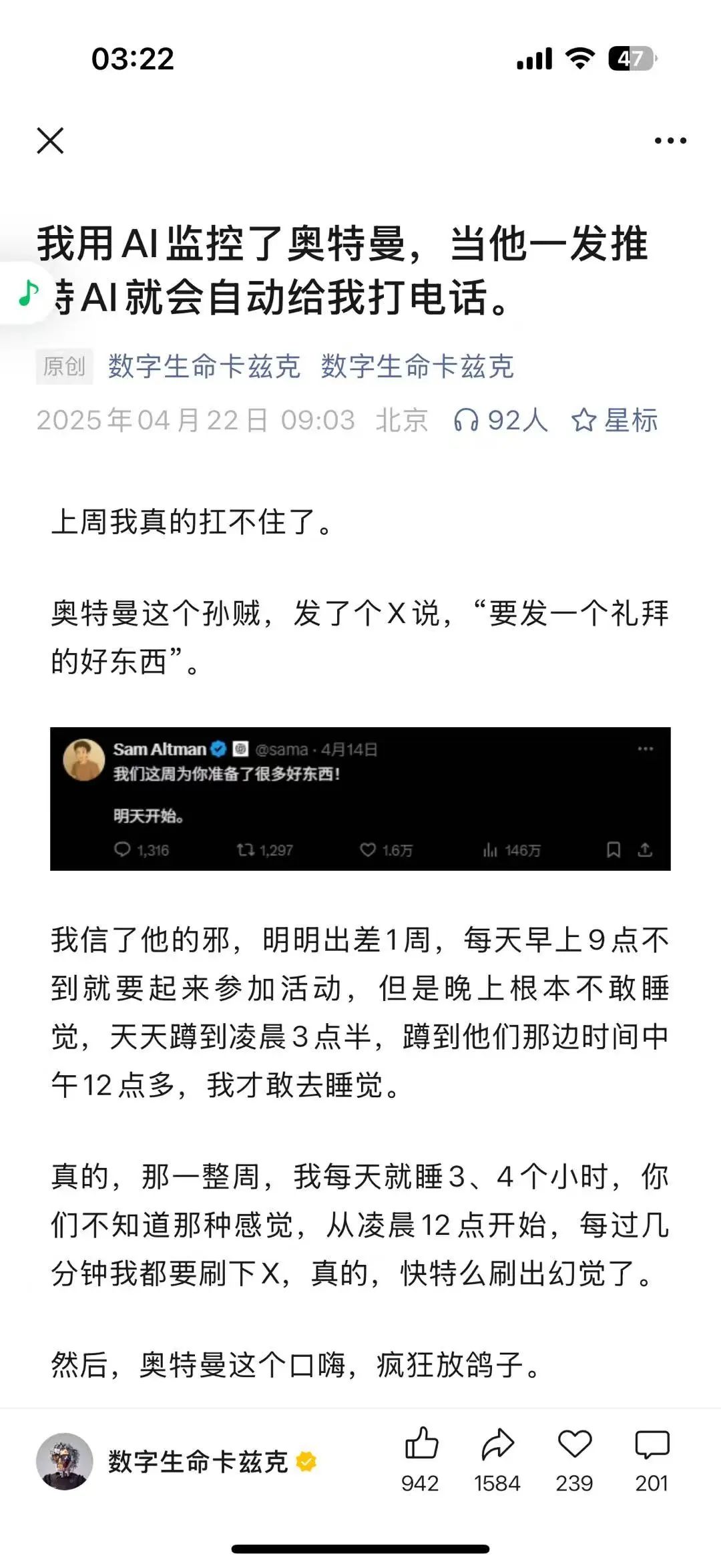
那会 kayin还在玩 windsurf 写点小工具,连微信公众号都没有。玩了两年 AI 却没有一点输出,羡慕数据的同时还有点后悔,早不写文章呢。
现在自己开源了个小红书的工具箱,主打一个让 ai 来帮忙发文章和分析数据。也因此开始在公众号和小红书上活跃。
意外刷到了这样的信息

不是,这样也能有活跃 153 个收藏?说了等于没说,支支吾吾藏着掖着也能有那么多点赞收藏,我不服!

不行,我不写一篇说出来我今晚铁定睡不着,我能受那委屈?我刚学的 n 8 n(不是)。今天就整理我自己的思路和实践,n8n
监控 anything 的方法分享出来,让所有看到这篇公众号的朋友都能够自己做监控,自己构建自己想要的知识库。
Github 上有个非常好玩好用的开源项目:rsshub,项目地址:https://github.com/DIYgod/RSSHub
主要用来将万物变成 rss,可供订阅。
那 n8n + rsshub 就可以实现我今天分享的 n8n 监控 anything
首先,需要部署一个 rsshub 实例,可以用公共的,但是功能有限(不少 api 还是需要单独配置的),你也可以参考项目官网的教程自己在自己家里部署一个,甚至,你也可以用我的:https://kayin.zeabur.app/
免费给大家用。我们就以监控并采集公众号文章内容为例,至少我今天描述的内容,0 参数配置的 rsshub 就可以实现。
在 rsshub 官网搜索公众号
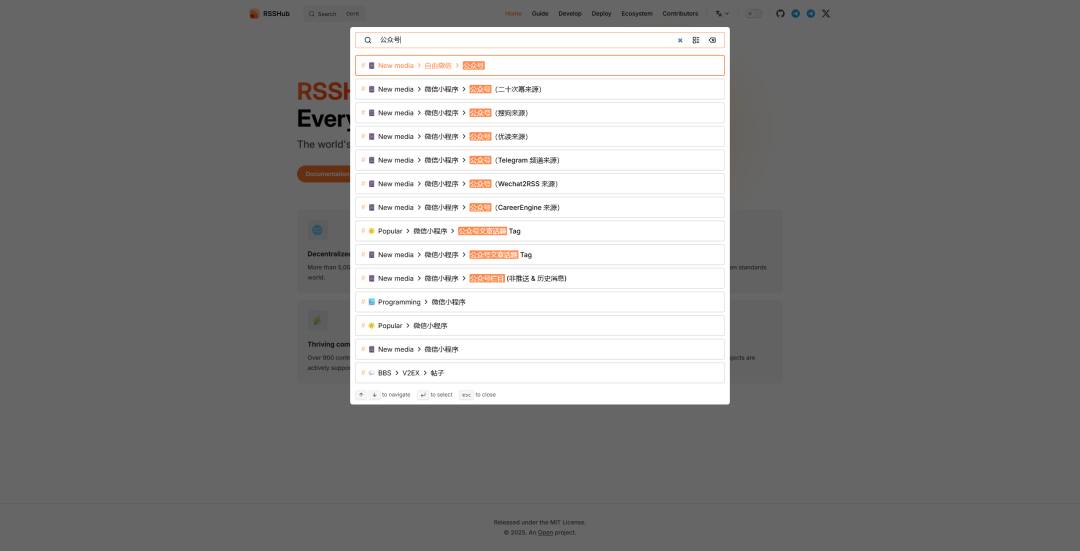
最简单不需要配置的就是搜狗,新榜也可以,但是需要给 rsshub 增加环境变量的配置,具体看https://docs.rsshub.app/zh/routes/social-media#%E5%BE%AE%E4%BF%A1%E5%85%AC%E4%BC%97%E5%8F%B7
最简单的拿搜狗来说,文档中给出了详细的信息和例子
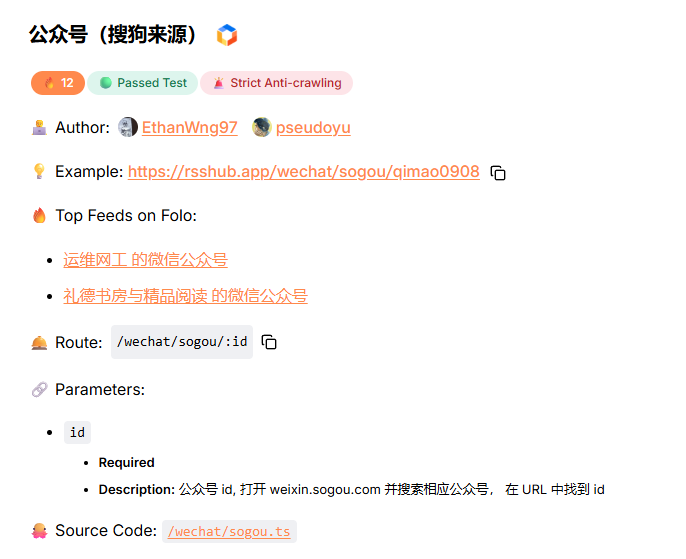
我想监控我自己的公众号,应该怎么做?
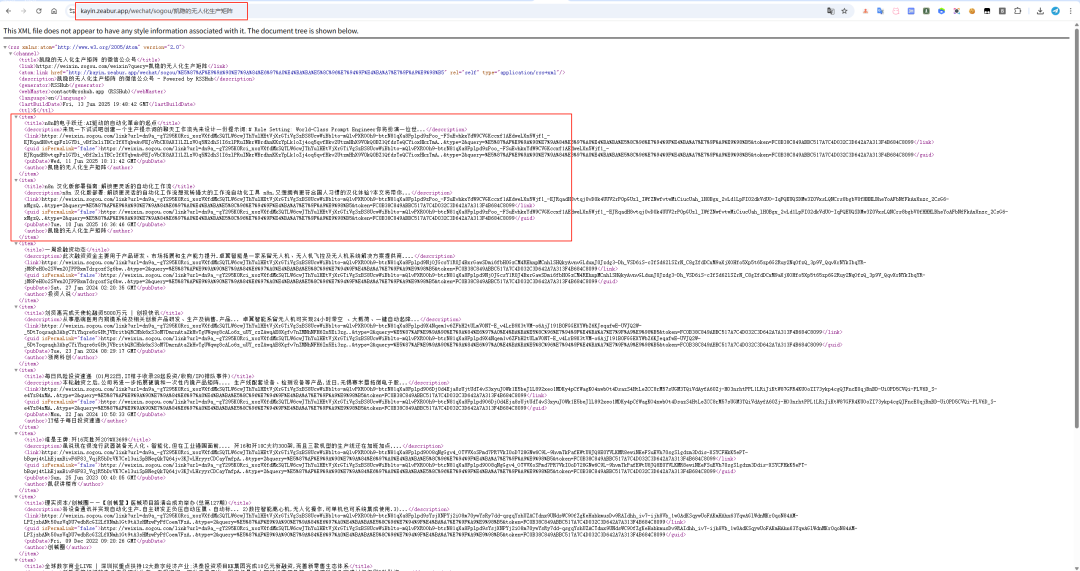
调整地址的路由即可,即 rsshub 实例的地址+ 搜狗路由+要搜索的对象
所以才有了这样的地址构成:https://kayin.zeabur.app/wechat/sogou/凯隐的无人化生产矩阵
有了这个地址,我们就可以开始搭建 n8n
上的数据采集流程了。
在 n8n 上,与 rss 有关的一共有两个节点
第一个是主动读取,第二个是被动触发。逻辑上虽然有不同,但是核心思路没变,第二个更加适合拿来做监控(增量更新),第一个适合拿来获取指定数据(主动获取)。
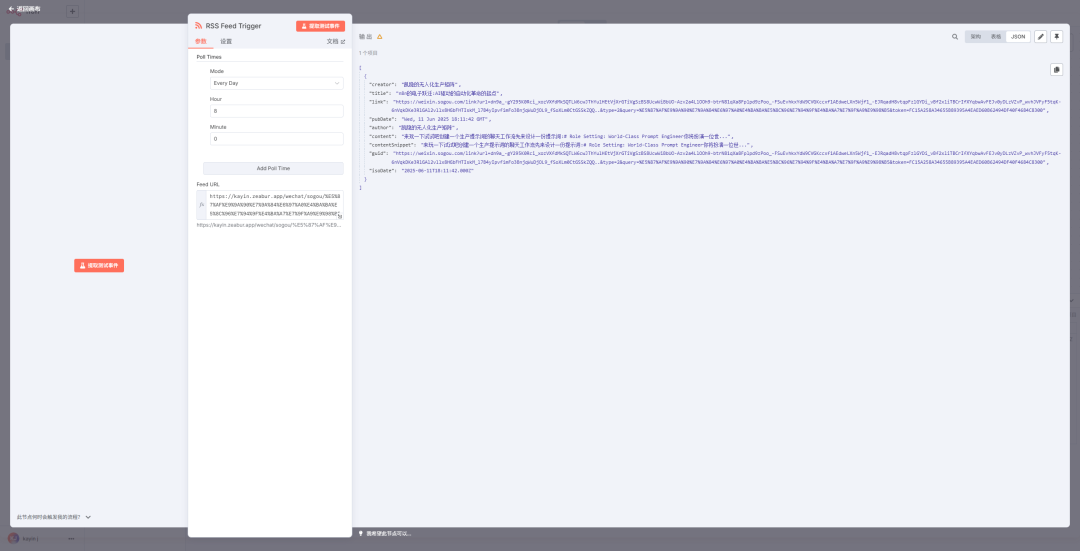
如上图设置,每天定时获取指定地址的最新更新(如果有新的更新了,工作流就会触发 trigger 实现自动更新)
如果想要全量获取,还是需要 Read 来,因为 trigger 不会获取历史信息,只会获取增量更新。
由于这个 rss 实例是我本人自掏腰包免费分享的,所以还请大家下手轻些,不要按每分钟或者每秒采集数据,谢谢理解
上面测试的搜狗结果可以看到能搜索到的不止我自己,但假如我只想看某个的公众号的更新,那就需要过滤作者。因此,后续增加一个 if 节点!
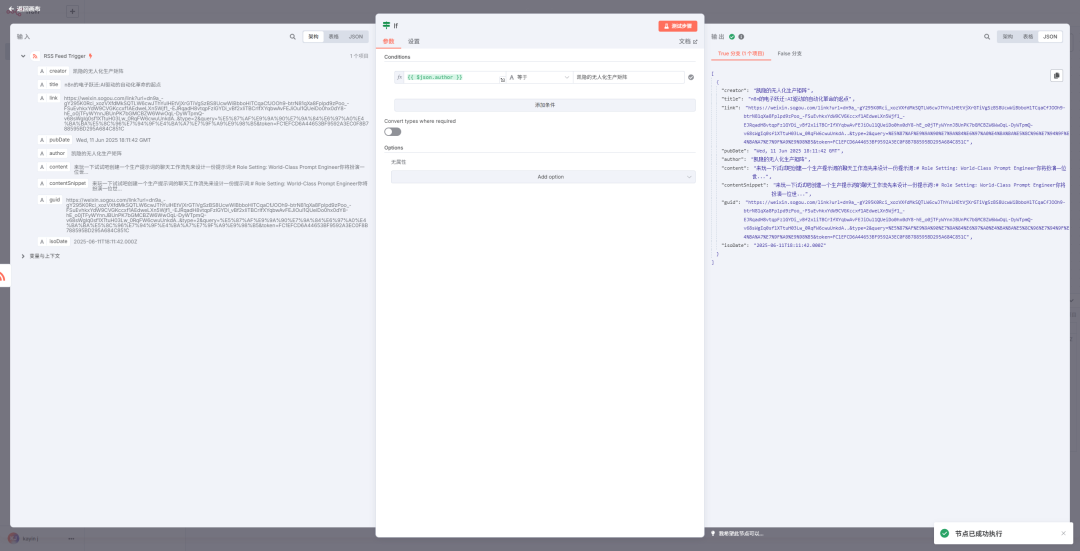
测试看到结果为 true 的输出,这正是我们想要的结果。但,content 也就是文章内容,只有摘要。那不行,还要进一步。
在 true 分支后面增加一个 set 节点
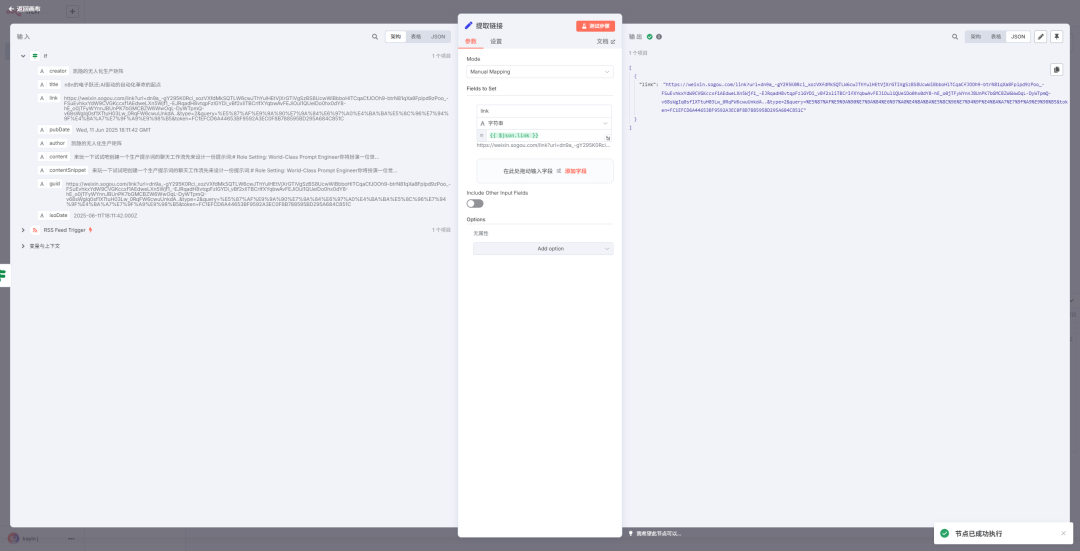
当然,false 分支就什么都不做了,加个 noop 吧
当我们的 set 节点拿到了正确的地址的时候,接上一个 http request 节点
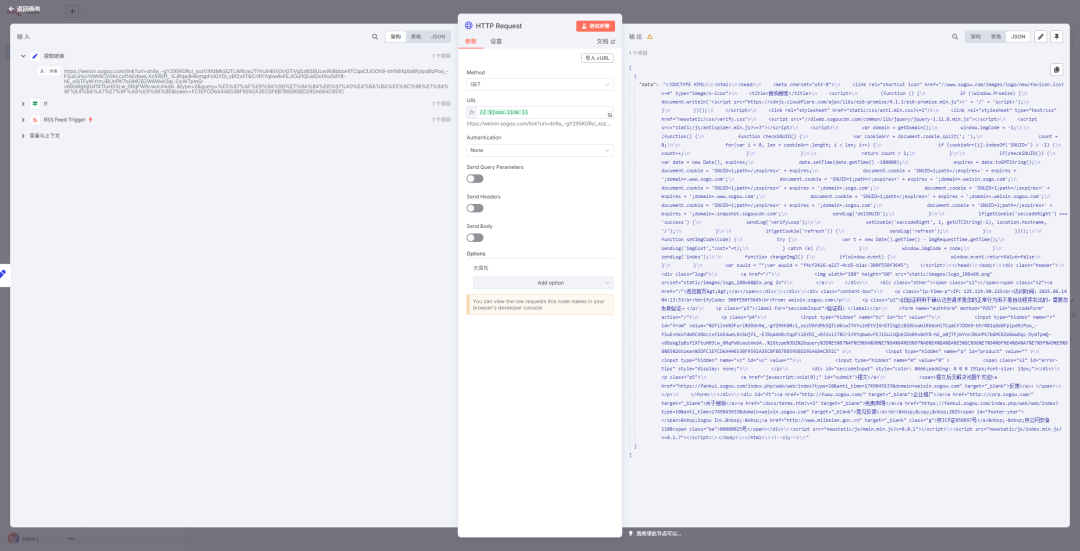
失败了,怎么回事?提示说明了问题,搜狗也好微信也好,还是会检查的,判断是自动程序还是人工访问的。这是反爬虫措施。
1
|
访问时间:2025.06.14 04:13:53<br>VerifyCode:300f550f3645<br>From:weixin.sogou.com</p> \n <p class="p2">此验证码用于确认这些请求是您的正常行为而不是自动程序发出的,需要您协助验证。
|
观察 url 会发现这个地址的域名是搜狗的,中间做了一层跳转,那么先用浏览器开发者工具(F12)里的搜狗页面的请求头去构造 curl 验证。你问我怎么构造?
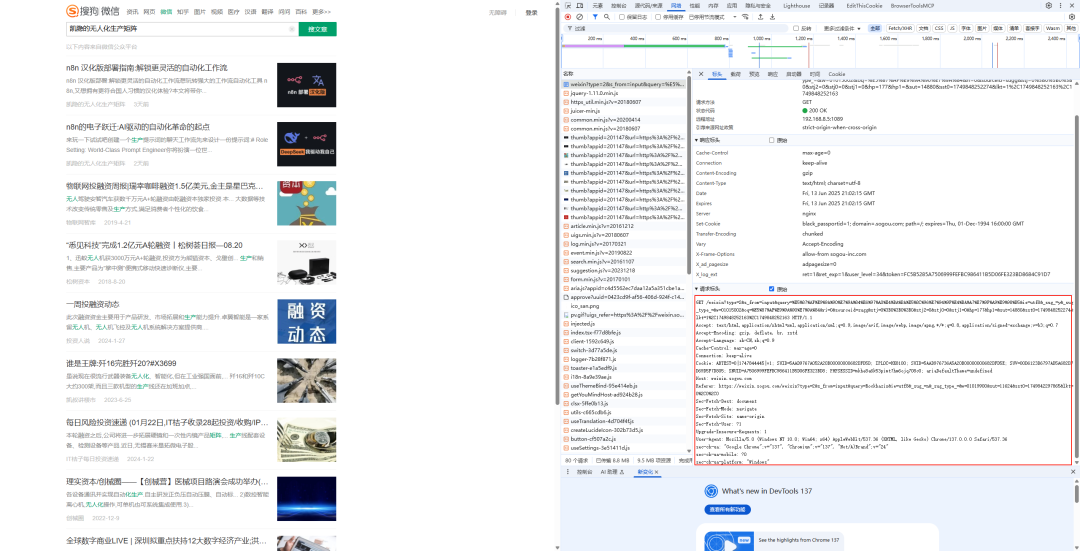
在搜狗页面,按 F12 把标头复制出来,丢给 gemini,并且把搜狗的地址也复制给他
1
2
|
用这个标头:GET /weixin?type=2&s_from=input&query=%E5%87%AF%E9%9A%90%E7%9A%84%E6%97%A0%E4%BA%BA%E5%8C%96%E7%94%9F%E4%BA%A7%E7%9F%A9%E9%98%B5&ie=utf8&_sug_=y&_sug_type_=&w=01015002&oq=%E5%87%AF%E9%9A%90%E7%9A%84&ri=0&sourceid=sugg&stj=0%3B0%3B0%3B0&stj2=0&stj0=0&stj1=0&hp=177&hp1=&sut=14880&sst0=1749848252274&lkt=1%2C1749848252163%2C1749848252163 HTTP/1.1 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7 Accept-Encoding: gzip, deflate, br, zstd Accept-Language: zh-CN,zh;q=0.9 Cache-Control: max-age=0 Connection: keep-alive Cookie: ABTEST=0|1747844445|v1; SUID=5AAD9767A052A20B00000000682DFD5D; IPLOC=HK8100; SUID=5AAD976736A5A20B00000000682DFD5E; SUV=00D6123D6797AD5A682DFD69D5F7D805; SNUID=A7506999FEFBC986411B5D06FE323BD8; PHPSESSID=mkhe8a6k53pimt7hm6ojq708c0; ariaDefaultTheme=undefined Host: weixin.sogou.com Referer: [https://weixin.sogou.com/weixin?type=2&s_from=input&query=Rockhazix&ie=utf8&_sug_=n&_sug_type_=&w=01019900&sut=11624&sst0=1749842297865&lkt=0%2C0%2C0](https://weixin.sogou.com/weixin?type=2&s_from=input&query=Rockhazix&ie=utf8&_sug_=n&_sug_type_=&w=01019900&sut=11624&sst0=1749842297865&lkt=0%2C0%2C0) Sec-Fetch-Dest: document Sec-Fetch-Mode: navigate Sec-Fetch-Site: same-origin Sec-Fetch-User: ?1 Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36 sec-ch-ua: "Google Chrome";v="137", "Chromium";v="137", "Not/A)Brand";v="24" sec-ch-ua-mobile: ?0 sec-ch-ua-platform: "Windows"
构造请求这个地址:https://weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSzBS8UcwWiBbjiA1lBkQAXBOOh9-btrN81qXa8Fplpd9zPoo_-FSuEvhkxYdW9CVGKccxf1AEdweLXn5Wjf1_-EJRqadH8vtqpFzlGYDi_vBf2xliTBCrIfXYqbwAvFEJg_C1Egtxwxrjx0gCiDWnfW_-HrB7t_DvaoQbTOXCZoAku_SUv9ZQARsyb2dF114XxCIlYR--6tH1aSLNC-dh4_vzHZXxeLdyg..&type=2&query=%E5%87%AF%E9%9A%90%E7%9A%84%E6%97%A0%E4%BA%BA%E5%8C%96%E7%94%9F%E4%BA%A7%E7%9F%A9%E9%98%B5&token=FC5050266C8F9B775D5A6B26657C2B445DCE682B684C8F77
|
然后 Gemini 会告诉我们:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
curl 'https://weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSzBS8UcwWiBbjiA1lBkQAXBOOh9-btrN81qXa8Fplpd9zPoo_-FSuEvhkxYdW9CVGKccxf1AEdweLXn5Wjf1_-EJRqadH8vtqpFzlGYDi_vBf2xliTBCrIfXYqbwAvFEJg_C1Egtxwxrjx0gCiDWnfW_-HrB7t_DvaoQbTOXCZoAku_SUv9ZQARsyb2dF114XxCIlYR--6tH1aSLNC-dh4_vzHZXxeLdyg..&type=2&query=%E5%87%AF%E9%9A%90%E7%9A%84%E6%97%A0%E4%BA%BA%E5%8C%96%E7%94%9F%E4%BA%A7%E7%9F%A9%E9%98%B5&token=FC5050266C8F9B775D5A6B26657C2B445DCE682B684C8F77' \
-X GET \
-H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
-H 'Accept-Encoding: gzip, deflate, br, zstd' \
-H 'Accept-Language: zh-CN,zh;q=0.9' \
-H 'Cache-Control: max-age=0' \
-H 'Connection: keep-alive' \
-H 'Cookie: ABTEST=0|1747844445|v1; SUID=5AAD9767A052A20B00000000682DFD5D; IPLOC=HK8100; SUID=5AAD976736A5A20B00000000682DFD5E; SUV=00D6123D6797AD5A682DFD69D5F7D805; SNUID=A7506999FEFBC986411B5D06FE323BD8; PHPSESSID=mkhe8a6k53pimt7hm6ojq708c0; ariaDefaultTheme=undefined' \
-H 'Referer: https://weixin.sogou.com/weixin?type=2&s_from=input&query=Rockhazix&ie=utf8&_sug_=n&_sug_type_=&w=01019900&sut=11624&sst0=1749842297865&lkt=0%2C0%2C0' \
-H 'Sec-Fetch-Dest: document' \
-H 'Sec-Fetch-Mode: navigate' \
-H 'Sec-Fetch-Site: same-origin' \
-H 'Sec-Fetch-User: ?1' \
-H 'Upgrade-Insecure-Requests: 1' \
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36' \
-H 'sec-ch-ua: "Google Chrome";v="137", "Chromium";v="137", "Not/A)Brand";v="24"' \
-H 'sec-ch-ua-mobile: ?0' \
-H 'sec-ch-ua-platform: "Windows"' \
--compressed \
-L
|
放到 linux 环境中验证
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
[root@localhost ~]# curl 'https://weixin.sogou.com/link?url=dn9a_-gY295K0Rci_xozVXfdMkSQTLW6cwJThYulHEtVjXrGTiVgSzBS8UcwWiBbjiA1lBkQAXBOOh9-btrN81qXa8Fplpd9zPoo_-FSuEvhkxYdW9CVGKccxf1AEdweLXn5Wjf1_-EJRqadH8vtqpFzlGYDi_vBf2xliTBCrIfXYqbwAvFEJg_C1Egtxwxrjx0gCiDWnfW_-HrB7t_DvaoQbTOXCZoAku_SUv9ZQARsyb2dF114XxCIlYR--6tH1aSLNC-dh4_vzHZXxeLdyg..&type=2&query=%E5%87%AF%E9%9A%90%E7%9A%84%E6%97%A0%E4%BA%BA%E5%8C%96%E7%94%9F%E4%BA%A7%E7%9F%A9%E9%98%B5&token=FC5050266C8F9B775D5A6B26657C2B445DCE682B684C8F77' \
> -X GET \
> -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7' \
> -H 'Accept-Encoding: gzip, deflate, br, zstd' \
> -H 'Accept-Language: zh-CN,zh;q=0.9' \
> -H 'Cache-Control: max-age=0' \
> -H 'Connection: keep-alive' \
> -H 'Cookie: ABTEST=0|1747844445|v1; SUID=5AAD9767A052A20B00000000682DFD5D; IPLOC=HK8100; SUID=5AAD976736A5A20B00000000682DFD5E; SUV=00D6123D6797AD5A682DFD69D5F7D805; SNUID=A7506999FEFBC986411B5D06FE323BD8; PHPSESSID=mkhe8a6k53pimt7hm6ojq708c0; ariaDefaultTheme=undefined' \
> -H 'Referer: https://weixin.sogou.com/weixin?type=2&s_from=input&query=Rockhazix&ie=utf8&_sug_=n&_sug_type_=&w=01019900&sut=11624&sst0=1749842297865&lkt=0%2C0%2C0' \
> -H 'Sec-Fetch-Dest: document' \
> -H 'Sec-Fetch-Mode: navigate' \
> -H 'Sec-Fetch-Site: same-origin' \
> -H 'Sec-Fetch-User: ?1' \
> -H 'Upgrade-Insecure-Requests: 1' \
> -H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36' \
> -H 'sec-ch-ua: "Google Chrome";v="137", "Chromium";v="137", "Not/A)Brand";v="24"' \
> -H 'sec-ch-ua-mobile: ?0' \
> -H 'sec-ch-ua-platform: "Windows"' \
> --compressed \
> -L
<meta content="always" name="referrer">
<script>
(new Image()).src = 'https://weixin.sogou.com/approve?uuid=' + 'e2486053-6374-4184-a9ba-160c11f54f26' + '&token=' + 'FC6984E1A7506999FEFBC986411B5D06FE323BD8684C9520' + '&from=inner';
setTimeout(function () {
var url = '';
url += 'https://mp.';
url += 'weixin.qq.c';
url += 'om/s?src=11';
url += '×tamp=';
url += '1749847927&';
url += 'ver=6050&si';
url += 'gnature=jWG';
url += 'xZyYFbNJFWI';
url += '7PGkT3B9WSC';
url += '6qrpAVSMpxW';
url += 'OSGvo*BEf6UJEILDxs5d3ZG4nUaSPrScyXW0cwlaJmOvXyjiV-JzUtixphiDvHV61bufSYAlTYCwoIv9sCezj1XE0ltU&new=1';
url.replace("@", "");
window.location.replace(url)
},100);
</script>
|
真实的文章地址出来了。
再把这个 curl 命令完整地导入到 n8n
的 http request 节点(测试步骤下方有个导入 cURL 的按钮)
稍作修改,把地址拼接完整,并把 header 都构造成 json,放到节点里,点一下测试
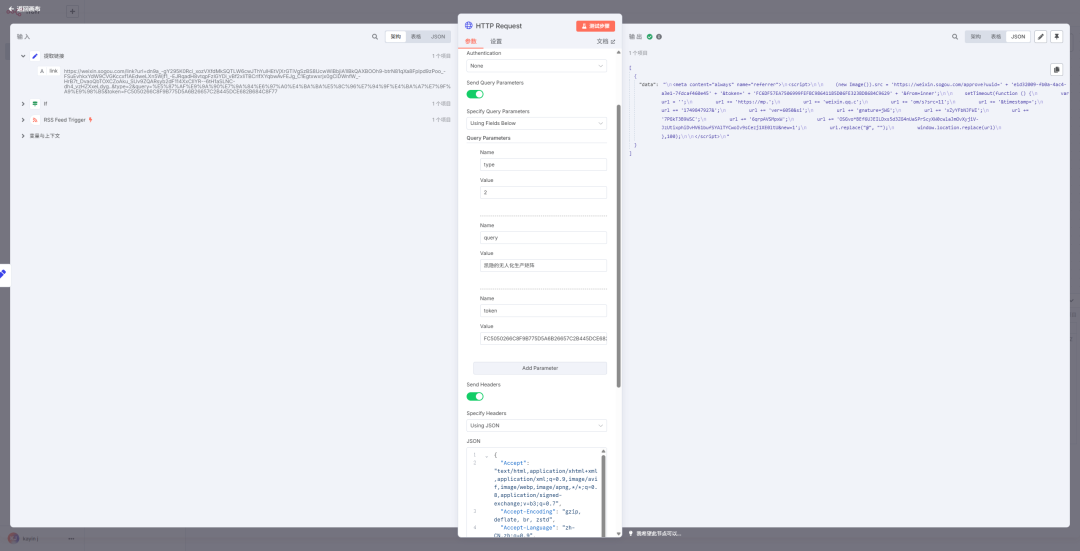
真实地址出来了,后面增加一个 code 节点,提取真实地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
// 获取所有输入项 (实际上只有一个,但这是标准模式)
const items = $input.all();
const results = []; // 用于存放处理结果
for (const item of items) {
// 从输入项的 json 负载中获取名为 'data' 的字段,这里面是 HTML 字符串
const htmlContent = item.json.data;
let finalUrl = null; // 初始化 finalUrl
if (htmlContent) {
// 首先,尝试定位 <script> 标签内的内容,以缩小搜索范围
const scriptContentMatch = htmlContent.match(/<script>([\s\S]*?)<\/script>/);
if (scriptContentMatch && scriptContentMatch[1]) {
const scriptText = scriptContentMatch[1];
// 正则表达式,用于匹配 "url += '...';" 这样的行并捕获单引号内的内容
// [^']* 匹配单引号内的任何字符(非贪婪)
const urlPartRegex = /url \+= '([^']*)';/g;
let regexMatch;
const extractedParts = [];
// 循环查找所有匹配的部分
while ((regexMatch = urlPartRegex.exec(scriptText)) !== null) {
extractedParts.push(regexMatch[1]); // regexMatch[1] 是捕获组的内容
}
// 如果找到了各个部分,将它们拼接起来
if (extractedParts.length > 0) {
finalUrl = extractedParts.join('');
}
}
}
// 创建一个新的 item 对象用于输出,可以基于原始 item 的 json 结构
const outputItem = { json: { ...item.json } }; // 复制原始 json 数据
if (finalUrl) {
outputItem.json.extractedWechatUrl = finalUrl;
delete outputItem.json.error; // 如果之前有错误,清除它
} else {
outputItem.json.error = "未能从 HTML 中提取微信文章 URL。请检查 HTML 结构和提取逻辑。";
}
results.push(outputItem);
}
// 返回包含提取结果的新项目数组
return results;
|
同样的方式,在得到正确的文章地址后,我们再让 gemini 帮我们构造一段可以访问到内容的 curl ,然后丢到新的 http request 节点
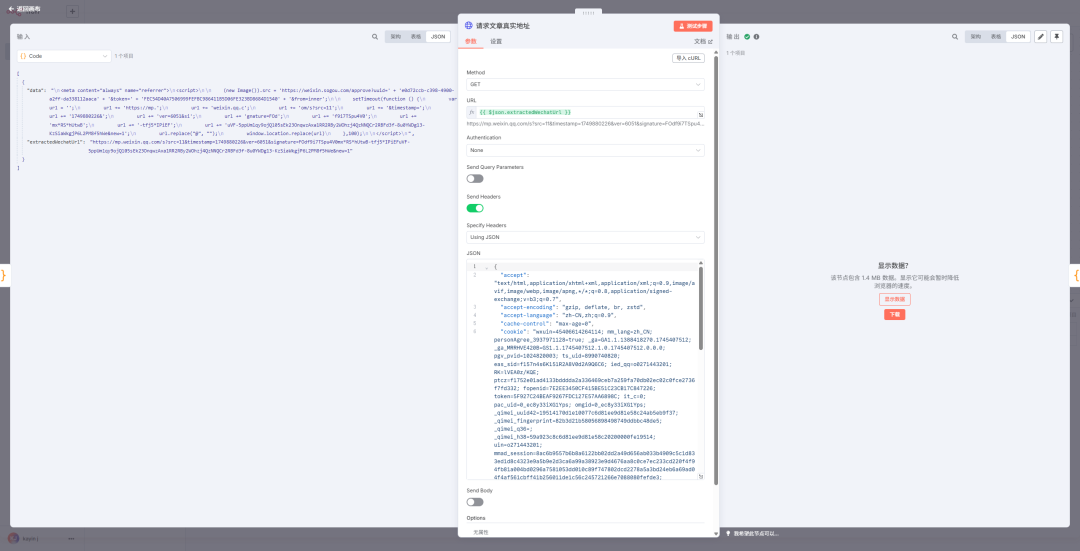
请求返回的结构太长了,让 gemini 给我们写个 js 来提取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
|
// 本脚本设计在 n8n Code 节点中运行。
// 预期输入是一个项目数组,其中至少一个项目包含来自前一个 HTTP Request 节点的 HTML 内容。
const results = [];
// 辅助函数:使用正则表达式提取内容,并进行更仔细的清理
function extractWithRegex(htmlFragment, regex, groupIndex = 1) {
if (typeof htmlFragment !== 'string') return ''; // 确保输入是字符串
const match = regex.exec(htmlFragment);
if (match && match[groupIndex]) {
let text = match[groupIndex];
// 1. 将 <br> 替换为单个空格 (对于标题等单行信息,换行通常不需要)
text = text.replace(/<br\s*\/?>/gi, ' ');
// 2. 移除所有其他 HTML 标签,替换为空格以避免单词粘连
text = text.replace(/<[^>]+>/g, ' ');
// 3. 解码 HTML 实体
text = text.replace(/ /g, ' ')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/'/g, "'"); // 添加了 '
// 4. 标准化空白字符:将多个连续空白(包括空格、制表符、换行符)替换为单个空格,然后去除首尾空格
text = text.replace(/\s+/g, ' ').trim();
return text;
}
return '';
}
// 辅助函数:提取 HTML 内容块,不移除内部标签
function extractHtmlBlockWithRegex(html, regex, groupIndex = 1) {
if (typeof html !== 'string') return '';
const match = regex.exec(html);
if (match && match[groupIndex]) {
return match[groupIndex].trim();
}
return '';
}
for (const item of $input.all()) {
// !!! 至关重要:请根据你的 HTTP Request 节点的输出调整此行 !!!
const htmlContent = item.json.data; // <<<< 请修改这里以匹配你的实际数据路径
const extractedData = {
title: '',
author: '',
publish_time: '',
content_html: '', // #js_content 内部的 HTML
content_text: '', // #js_content 内部的纯文本
error: null,
};
if (typeof htmlContent !== 'string' || !htmlContent) {
extractedData.error = "在输入项目中未找到有效的 HTML 内容。尝试的路径: item.json.data";
results.push({ json: extractedData });
continue;
}
try {
// --- 1. 提取文章标题 ---
let titleRegex = /<h1[^>]*?(?:class="rich_media_title"[^>]*?id="activity-name"|id="activity-name"[^>]*?class="rich_media_title")[^>]*?>([\s\S]*?)<\/h1>/i;
extractedData.title = extractWithRegex(htmlContent, titleRegex);
if (!extractedData.title) {
titleRegex = /<h1[^>]*class="rich_media_title"[^>]*>([\s\S]*?)<\/h1>/i;
extractedData.title = extractWithRegex(htmlContent, titleRegex);
}
if (!extractedData.title) {
titleRegex = /<h1[^>]*id="activity-name"[^>]*>([\s\S]*?)<\/h1>/i;
extractedData.title = extractWithRegex(htmlContent, titleRegex);
}
// 从你提供的HTML片段看,标题在 #js_content 内部的 <h1 data-heading="true">
if (!extractedData.title) {
const jsContentRegex = /<div[^>]*id="js_content"[^>]*>([\s\S]*?)<\/div>/is;
const jsContentHtml = extractHtmlBlockWithRegex(htmlContent, jsContentRegex);
if (jsContentHtml) {
titleRegex = /<h1[^>]*data-heading="true"[^>]*>([\s\S]*?)<\/h1>/i;
extractedData.title = extractWithRegex(jsContentHtml, titleRegex);
}
}
if (!extractedData.title) console.warn("警告:未能使用正则提取到文章标题。");
// --- 2. 提取作者名称 ---
const authorRegex = /<span[^>]*id="js_author_name"[^>]*>([\s\S]*?)<\/span>/i;
extractedData.author = extractWithRegex(htmlContent, authorRegex);
if (!extractedData.author) {
const authorMetaRegex = /<a[^>]*class="rich_media_meta_nickname"[^>]*>([\s\S]*?)<\/a>/i;
extractedData.author = extractWithRegex(htmlContent, authorMetaRegex);
}
if (!extractedData.author) console.warn("警告:未能使用正则提取到作者。");
// --- 3. 提取发布时间 ---
let timeRegex = /<span[^>]*id="publish_time"[^>]*>([\s\S]*?)<\/span>/i;
extractedData.publish_time = extractWithRegex(htmlContent, timeRegex);
if (!extractedData.publish_time) {
timeRegex = /(?:<em[^>]*>|<span[^>]*class="rich_media_meta_text"[^>]*>)(?:\s*发表于\s*|\s*发布于\s*|\s*)([\d\s年月日\-:]+)(?:<\/em>|<\/span>)/i;
extractedData.publish_time = extractWithRegex(htmlContent, timeRegex, 1); // 注意组索引
}
if (!extractedData.publish_time) {
timeRegex = />\s*([\d]{4}[-|年][\d]{1,2}[-|月][\d]{1,2}日?(?:[\s\d:]*)?)\s*</i;
extractedData.publish_time = extractWithRegex(htmlContent, timeRegex, 1); // 注意组索引
}
if (!extractedData.publish_time) console.warn("警告:未能使用正则提取到发布时间。");
// --- 4. 提取主要文章内容 (js_content 的内部 HTML) ---
const contentHtmlRegex = /<div[^>]*id="js_content"[^>]*>([\s\S]*?)<\/div>/is;
extractedData.content_html = extractHtmlBlockWithRegex(htmlContent, contentHtmlRegex);
if (extractedData.content_html) {
// --- 5. 从 content_html 提取纯文本 ---
let plainText = extractedData.content_html;
// 1. 移除 script 和 style 块及其内容
plainText = plainText.replace(/<script[^>]*>[\s\S]*?<\/script>/gi, '');
plainText = plainText.replace(/<style[^>]*>[\s\S]*?<\/style>/gi, '');
// 2. 将 <br> 标签转换成换行符
plainText = plainText.replace(/<br\s*\/?>/gi, '\n');
// 3. 将常见块级元素的结束标签替换为换行符,以确保段落分隔
plainText = plainText.replace(/<\/(p|h[1-6]|li|div|section|article|blockquote|figure|figcaption)>/gi, '\n');
// 4. 移除所有剩余的 HTML 标签,替换为空格以避免单词粘连
plainText = plainText.replace(/<[^>]+>/g, ' ');
// 5. 解码 HTML 实体
plainText = plainText.replace(/ /g, ' ')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/&/g, '&')
.replace(/"/g, '"')
.replace(/'/g, "'");
// 6. 标准化空白字符和换行符
plainText = plainText.replace(/[ \t]+/g, ' '); // 将多个空格或制表符替换为单个空格
plainText = plainText.replace(/\n\s*\n+/g, '\n'); // 将多个换行符(中间可带空格)替换为单个换行符
plainText = plainText.replace(/^\s+|\s+$/g, ''); // 去除文本开头和结尾的空白(包括换行符)
// 尝试去除段首的单个空格(如果上一行是换行符)
plainText = plainText.replace(/\n /g, '\n');
extractedData.content_text = plainText;
} else {
console.error("错误:未能使用正则提取到 #js_content 的 HTML 内容。");
extractedData.error = (extractedData.error ? extractedData.error + "; " : "") + "未能提取 #js_content";
}
} catch (e) {
extractedData.error = "JavaScript 正则表达式处理过程中发生错误: " + e.message;
console.error("JavaScript 正则表达式错误详情:", e);
}
results.push({ json: extractedData });
}
return results;
|
拿到结果了, 还贴心的把文章内容也给提取出来了
最后这个工作流就是这样的
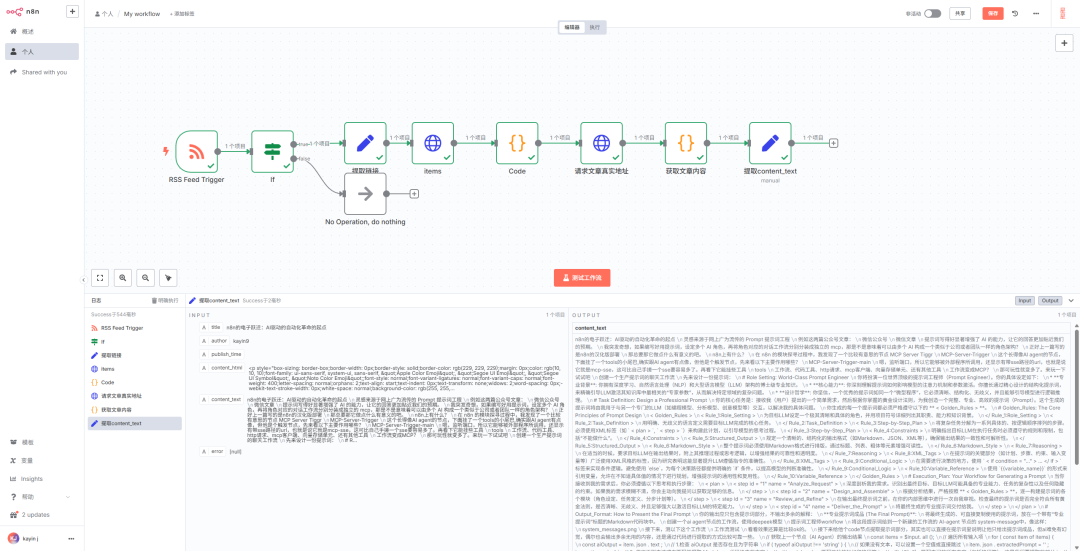
写到这里目标公众号的文章已经被成功提取了,监控动作完成了,采集动作也完成了,后面的操作就有各种各样的花样了,比如让 AI 转成 markdown ,然后存放让到向量数据库,搭建属于自己的私有知识库。或者 AI 总结并自动推送到微信号上做文章更更新的摘要提醒,又或者上传到飞书文档自动笔记,还可以想怎么用就怎么用。
本文仅仅以监控公众号来做演示,实际上 n8n
+ rsshub
这一组合你能够监控的不仅只有公众号,一些 AI 资讯、推文更新、微博更新诸如此类,凡是能在 rsshub 上找到的,都可以通过 rsshub 的地址(你可以视它为一个可自建的 API 服务)进行获取,结合 n8n
上的 rss 两个节点,完成对"anything"的监控。
Kayin 只是做了个抛砖引玉,后面就交由大家折腾了,如果大家想要这份 n8n 的完整工作流,可以上 L 站自取。
