核心内容:
- Index-1.9B模型包含base、pure、chat和character四个版本。
- 预训练阶段,WSD的decay阶段加入高质量数据和指令数据能提升下游任务效果。
- SFT时加载预训练优化器参数有收益,Norm-Head能稳定预训练过程。
源自 | HZLin Linsight 2024-07-07 12:35
bilibili发布的Index-1.9B包含:
-
Index-1.9B base:在2.8T语料训练的基模型
-
Index-1.9B pure:部分数据和base不同,其他相同
-
Index-1.9B chat:基于base进行SFT和DPO后的模型
-
Index-1.9B character:在chat的基础上用RAG+fewshots提供角色扮演的能力
下面看下细节。
模型
(1)模型深度
目前业界普遍的认知是模型深度比宽度对效果的影响更大(相同参数下)。对比层数分别为36层和9层,总参数都为1.01B的模型,结果如下图,36层模型(base)效果确实更好。
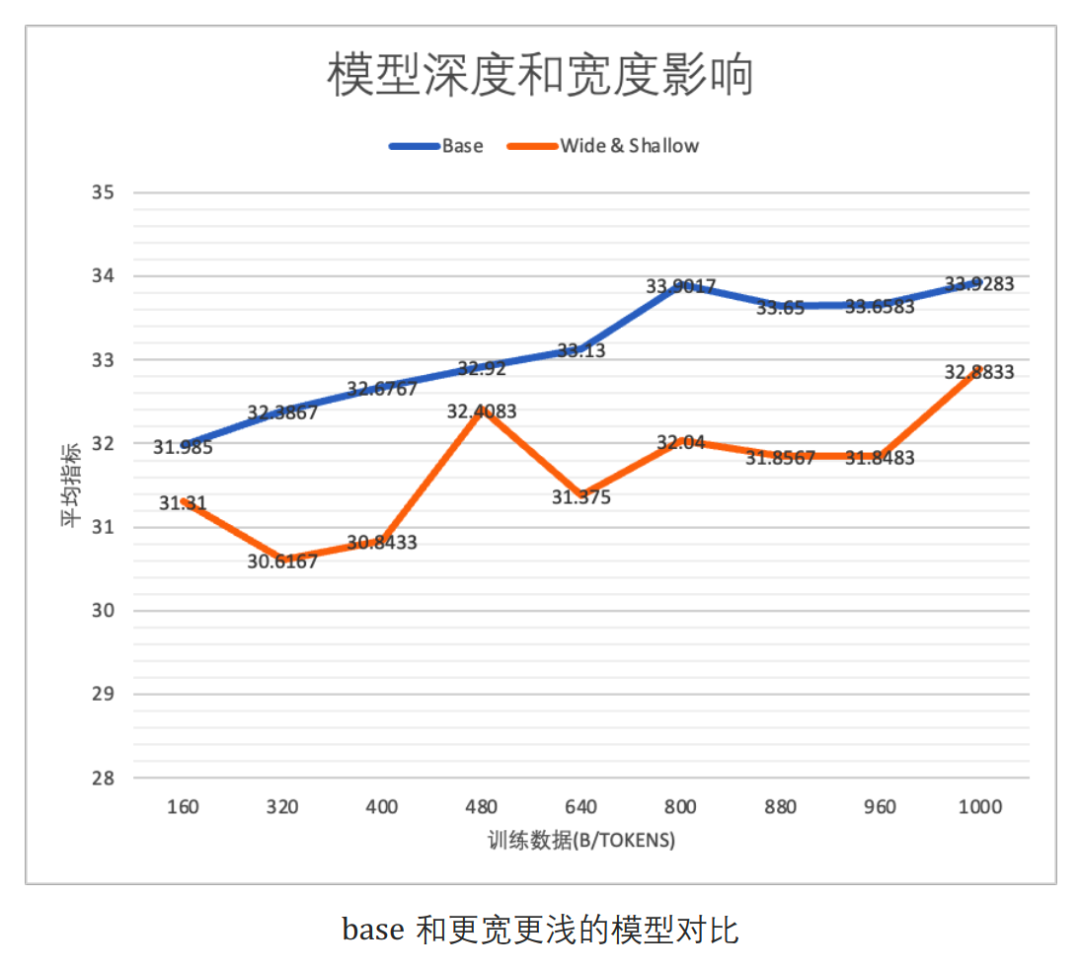
需要注意的是,相同模型参数量下,层数更多的模型会有更多的activation(与L * hidden size成正比),因此会需要更多显存。
(2)Norm-Head
模型不同层的梯度尺度分布非常不同,最后一层 LM-Head 的梯度,占据了绝大部分的梯度大小。而词表的稀疏性让 LM-Head 层稳定性较低,影 响模型训练稳定性,进而影响模型性能表现,所以稳定的 LM-Head 层对于训练非常重要。
参考Baichuan2使用Norm-Head,即对LM-Head进行Norm,能让训练更稳定。
对比有无Norm-Head的模型,效果和Gradient Norm具体情况如下图
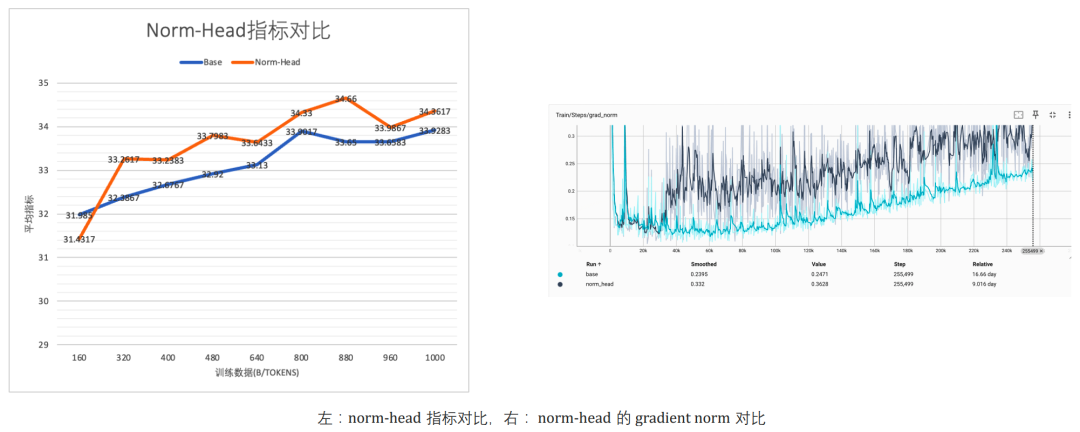
Norm-Head版本的效果更好,Gradient Norm整体变化也比较小,相对稳定(除了开头有个突升)。
预训练
数据
数据一些细节:
-
总量2.8T
-
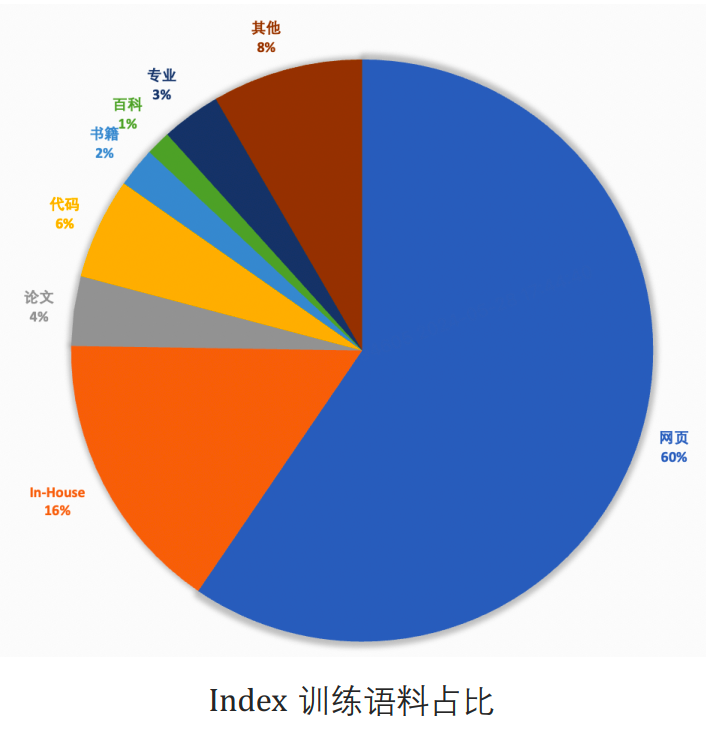
中文:英文 = 4:5,代码占比 = 6%
-
书籍、百科、论文、STEM相关精选数据占比10%,这部分很重要
具体占比饼图如下

数据去重上做了一个事情:如果预先分局分段就有可能有一些重复没有被发现,因此这里采用支持任意长度、任意位置的文档内字符串去重。实现上基于https://github.com/google-research/deduplicate-text-datasets进行了优化。
支持任意位置所能找到的难以发现的重复片段例子如下图。月份下拉框文字,重复了 15.6w 次,只能通过精准字符串去重识别

训练数据在packing的时候,重置了attention-mask和position-id。
训练
(1)训练设置
-
AdamW,beta_1=0.9,beta_2=0.95,eps=1e-8
-
gradient clip=1.0
-
weight decay=0.1
(2)lr和scheduler
训练的时候使用WSD的learning rate scheduler,分为了两阶段的训练:
-
warmup 100步 + 全局混合数据
-
decay阶段,增大精选数据比例
这里把decay阶段设得比较长,最大lr为5e-4,decay结束时减小到1%即5e-6,整个decay过程训练了400B数据。
这里还用0.1B的模型,分别用Cosin、Linear和WSD训练1T的数据,训练过程的loss和最终模型的效果对比如下
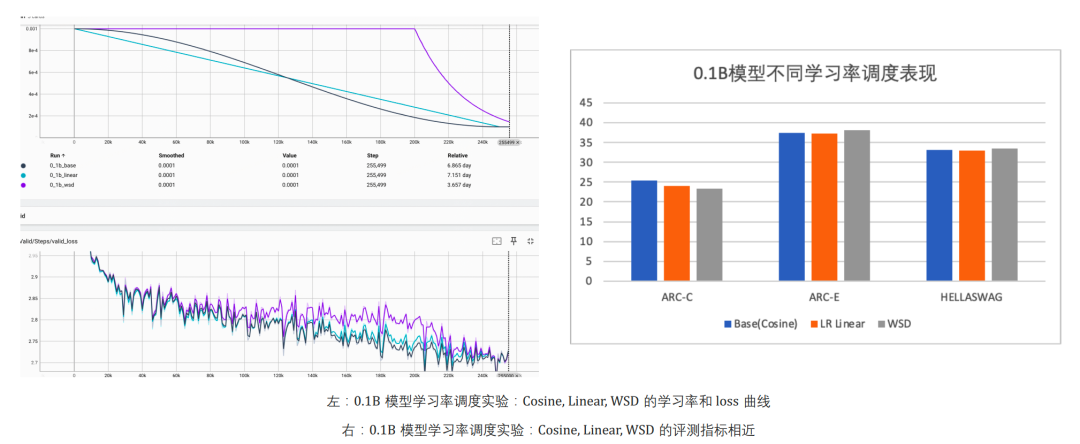
几个发现:
-
最终三种scheduler的valid loss都收敛到同一个水平
-
WSD在S阶段的valid loss比较高,而在decay阶段会快速下降
-
评测指标整体没有差太多
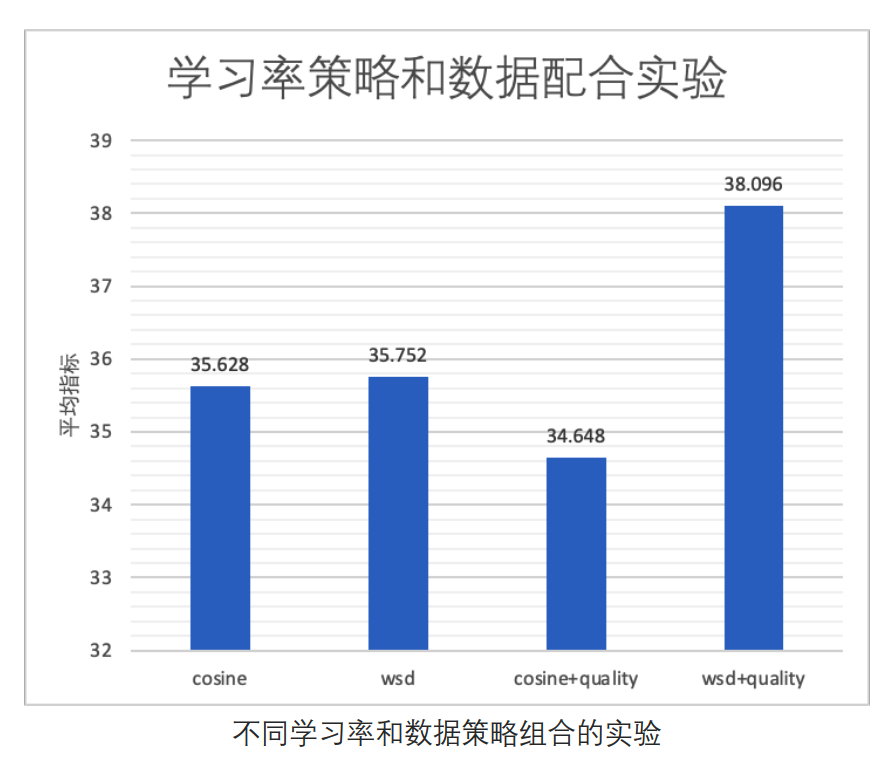
(3)decay阶段数据的配合
从上面的实验发现WSD在decay阶段的loss会快速下降,那么在这个阶段加入更多的高质量精选数据应该有更好的效果。
为了验证这个想法,用以下四种配置做实验:
-
Cosine
-
WSD
-
Cosine + 后10%加入更多精选数据
-
WSD + 后10%进入decay阶段,并加入更多精选数据
评测结果如下,确实是在decay阶段增加高质量数据的WSD效果最好。
(4)预训练阶段加入指令数据
在decay阶段还做了一个实验,验证加入指令数据对最终预训练模型效果的影响。
为了验证效果,训了两个版本的模型:
-
index-1.9b-ablation-pure:Decay 阶段自然文本数据,精选数据做重新放入增加浓度(书籍、论文、百科、专业等类别)
-
index-1.9b-ablation-boost:在pure基础上,额外加入占比7%的指令数据
在MMLU的效果对比如下
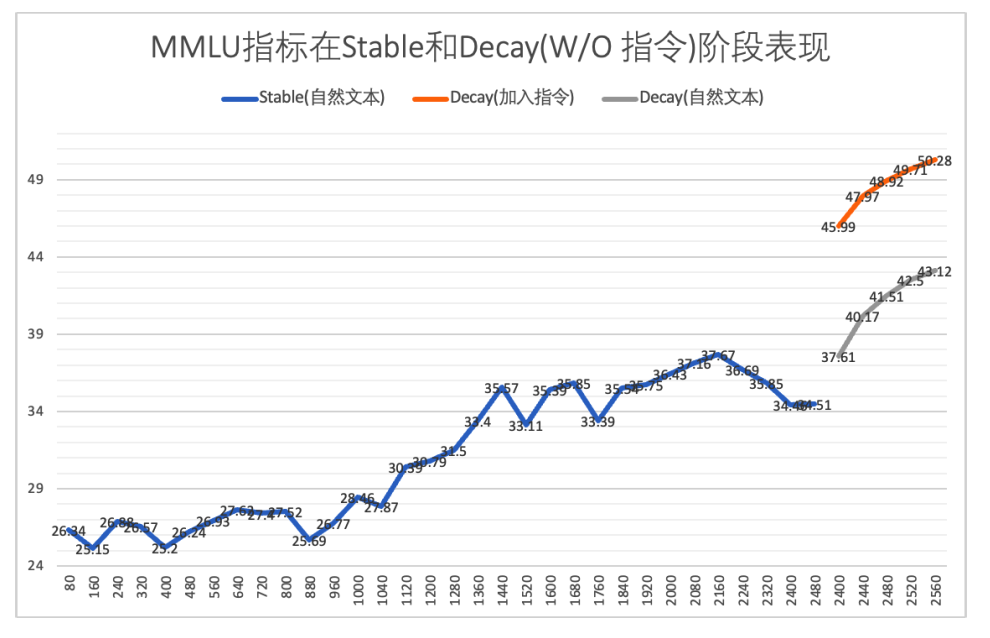
在decay阶段增加指令数据能明显提升下游任务指标。
对齐
SFT
(1)数据
-
使用10M中英数据
-
使用奖励模型打分进行筛选清洗
-
参照了主流的聚类增强多样性
-
对缺少指令数据的任务,构造/标注进行补充
(2)训练
-
lr=1e-5
-
采用 system-query-response 格式
实验还发现,SFT时,加载预训练优化器的参数,并加入部分预训练语效果最好。预训练语料和SFT数据response的token数占比为4:6。

DPO
这里开发人员认为评价标准偏判别而非枚举的任务通过偏好学习可以取得最大的收益,因此DPO主要针对写作类、指令遵循和安全进一步对齐。
此外在构造安全类数据的时候,发现通过prompt让模型生成拒答回复,比人写好,原因是人工构造的拒答样本在 SFT 模型中的 ppl 过高,如果强行对齐又会导致拒答率较高,带来灾难性遗忘。
lr = 1e-6 scheduler = cosine epoch = 1 dpo 超参beta = 1
评测结果如下

小结
Index-1.9B验证了几个事情:
-
在WSD的decay阶段加入高质量预训练数据,以及指令数据,对下游任务效果有明显提升。
-
SFT时加载预训练优化器参数有收益。
-
Norm-Head能稳定预训练过程。
读到这了,来一发点赞收藏关注吧~
Reference
1】https://github.com/bilibili/Index-1.9B/blob/main/Index-1.9B%20%E6%8A%80%E6%9C%AF%E6%8A%A5%E5%91%8A.pdf