- DeepSeek发布V3.1模型,上下文长度扩展至128k
- Google承诺修复Gemini API的截断及空回复问题
- AGENTS.md工作组推出编码Agent开放标准
源自 | Juya橘鸭Juya 2025-08-20 08:17
概览
-
DeepSeek发布V3.1模型 #1
-
Google 承诺即将修复 Gemini API 截断及空回复问题 #2
-
AGENTS.md工作组成立 推出编码Agent开放标准 #3
-
谷歌新模型 nano-banana 现身 LMArena #4
-
Google Whisk 扩展至77国并集成Veo 3 #5
-
阿里云百炼上架Qwen-VL-Plus新版 #6
-
Kilo Code更新:新增基于用量的价格估算与QwenCode支持 #7
-
Augment Code推出Agent Turn Summary功能 #8
-
OpenAI在印度推出ChatGPT Go订阅服务 #9
-
Microsoft Excel 推出 =COPILOT() 函数 #10
-
腾讯推出卡通制作工具ToonComposer #11
-
Firecrawl发布V2版本 #12
-
Allen Institute for AI 发布 OLMo 2 1B 早期训练检查点 #13
-
Cursor发布全球最快MXFP8 MoE内核 #14
-
苹果Xcode 26将原生集成Claude模型 #15
-
字节跳动即将发布开源模型SeedOss-36B #16
-
字节跳动研发AI手机 #17
-
英伟达为中国开发两款Blackwell架构AI芯片 #18
-
谷歌宣布首座AI数据中心核反应堆所在地 #19
-
Meta 正式宣布重组AI部门 #20
DeepSeek发布V3.1模型 #1
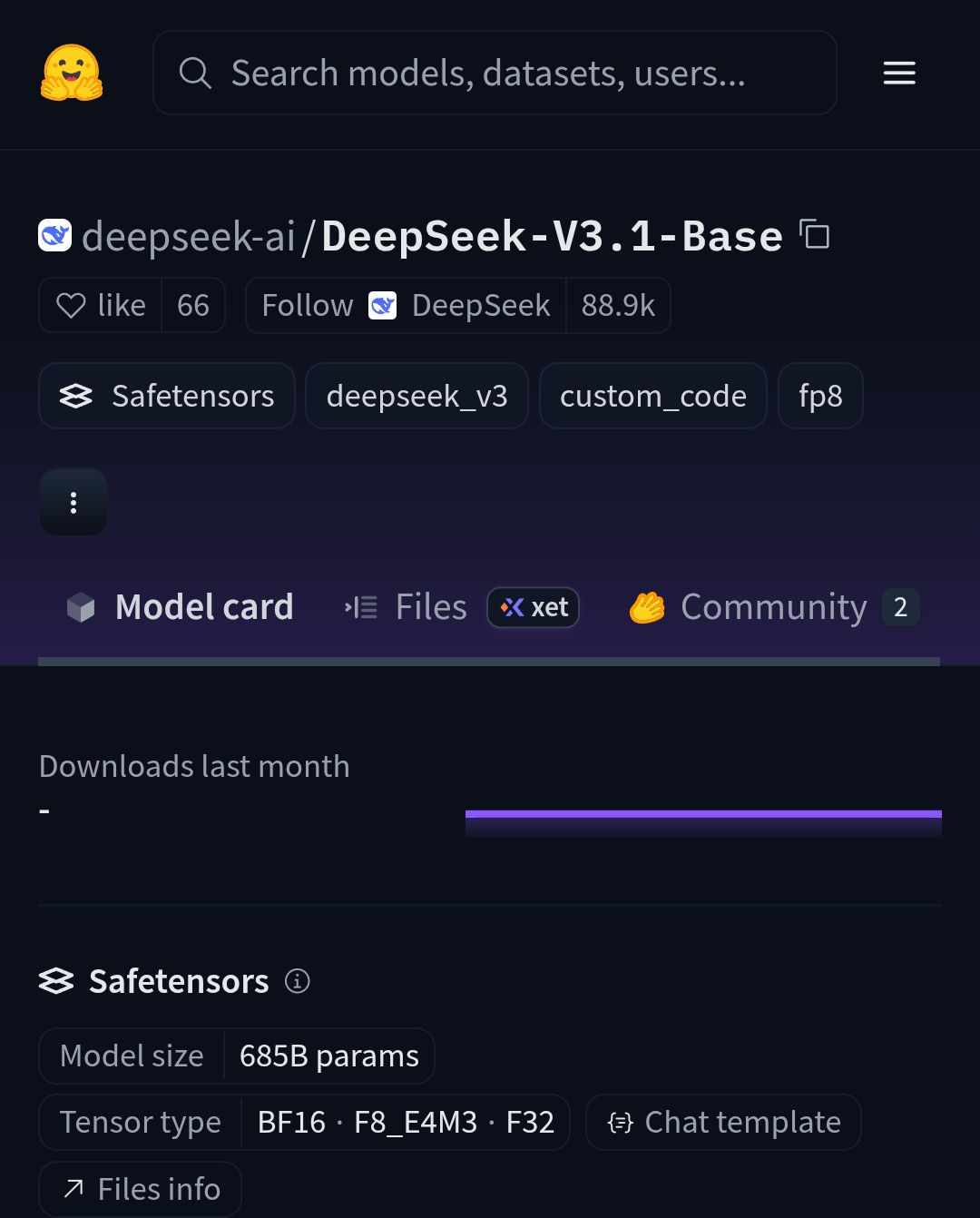
DeepSeek发布模型DeepSeek-V3.1版本,上下文长度扩展至128k,其Base模型也已在HuggingFace发布。
DeepSeek宣布其线上模型已升级至V3.1版本,此次更新将官方API和网页服务的上下文长度拓展至128k。目前V3.1版本已在官方网页、APP以及微信小程序和API中上线。
与此同时,DeepSeekV3.1的Base模型(DeepSeek-V3.1-Base)也已在Hugging Face上发布,尽管模型卡片最初尚未更新,但相关文件已上传可供下载。 有观察指出,V3.1模型是一个混合推理模型,目前在官网中启用深度思考模式会调用V3.1模型的推理模式。并且,V3.1的网页版即使在关闭搜索功能的情况下也会主动进行搜索,除非在提示中明确指示“不要搜索”,这可能与新引入的特殊tokens设计有关。 目前DeepSeek尚未发布正式公告,本报会持续跟进报道。


|
|
Google 承诺即将修复 Gemini API 截断及空回复问题 #2
谷歌官方回应将尽快修复Gemini 2.5 Pro模型API存在的回复截断和空回复问题。
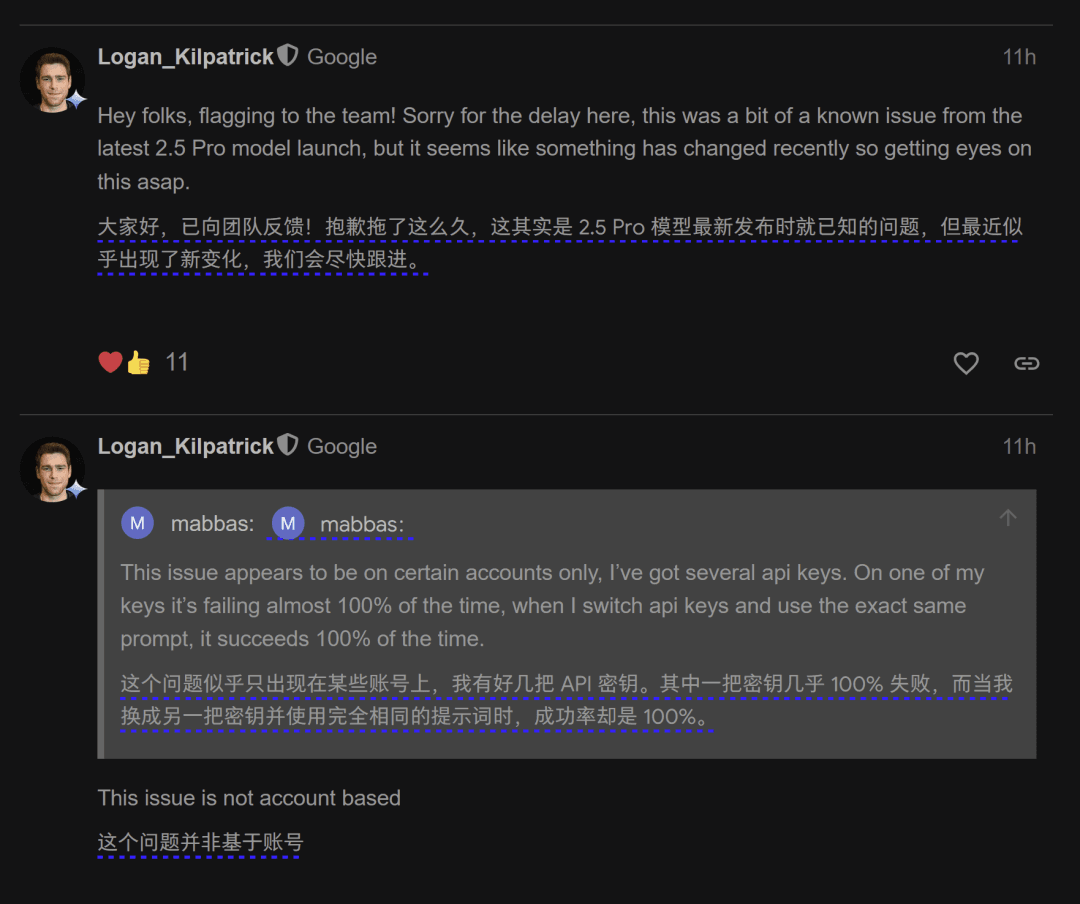
自前段时间以来,Google 的 Gemini 2.5 Pro 模型 API 出现了广泛的回复截断和空回复问题。该问题影响全球用户,无论是使用免费还是付费 API key 的开发者都受到了同等影响。
GeminiAPI 负责人 Logan Kilpatrick 昨晚回应称:“大家好,已向团队反馈!抱歉拖了这么久,这其实是 2.5 Pro 模型最新发布时就已知的问题,但最近似乎出现了新变化,我们会尽快跟进。”
这意味着,该问题或将很快得到修复。
|
|
AGENTS.md工作组成立 推出编码Agent开放标准 #3
一个由多家公司组成的工作组推出了名为AGENTS.md的开放标准,旨在为编码Agent提供统一、清晰的指令格式。
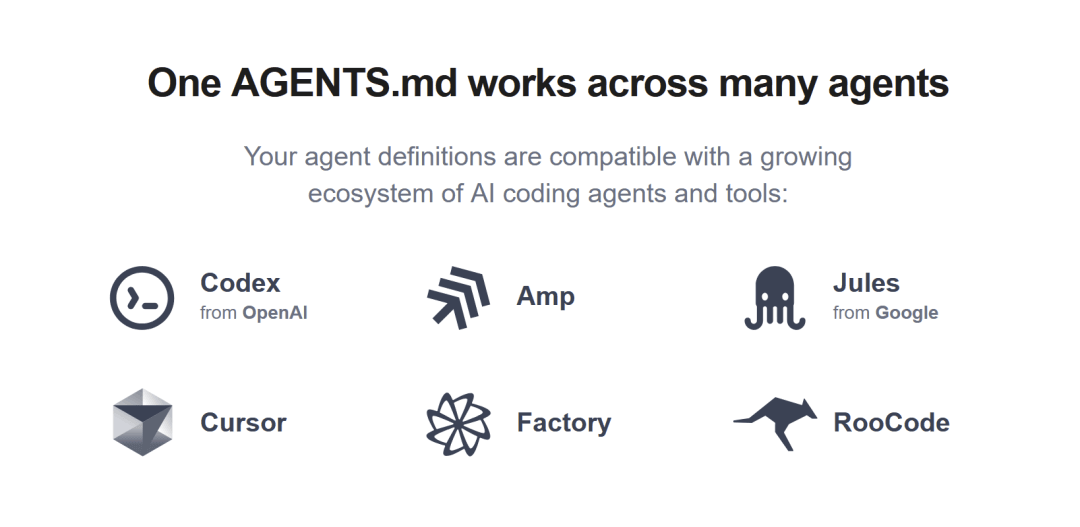
一个由OpenAI Codex、Amp、Google Jules、Cursor、RooCode和Factory组成的AGENTS.md工作组宣布,正式推出一个名为AGENTS.md的单一、开放且供应商中立的标准,旨在指导编码Agent在代码库中的工作方式。该格式的官方网站agents.md现已上线。
AGENTS.md被定位为“为Agent设计的README”,是一个简单、开放的格式,用于向编码Agent提供指导。其设计初衷是为了补充专为人类开发者设计的README.md文件。README.md通常包含快速入门、项目描述和贡献指南,而AGENTS.md则专注于提供编码Agent所需的额外、详细的上下文信息,例如构建步骤、测试指令、项目结构、代码约定和安全注意事项等。这种分离设计旨在为Agent提供一个清晰、可预测的指令来源,同时保持README.md 对人类贡献者的简洁性和专注度。
使用AGENTS.md的方法很简单:在代码仓库的根目录下创建一个AGENTS.md文件。对于大型的monorepo,可以在每个子项目或包内放置一个嵌套的AGENTS.md文件。Agent会自动读取目录树中最近的该文件,使其指令具有针对性,最接近的配置文件将拥有优先权。
目前,该标准已获得Cursor、Amp、Jules、Factory、RooCode和Codex等多种AI编码Agent和工具的支持。
|
|
谷歌新模型 nano-banana 现身 LMArena #4
谷歌代号为nano-banana的新图像生成模型已在LMArena平台进行测试,其性能据称超越了GPT-Image-1。
大量谷歌工作人员在社交平台上发布香蕉emoji或香蕉图片,明示代号为 nano-banana 的图像生成模型为谷歌所有。
目前该模型在 LMArena 平台进行测试,但尚未在 AI Studio 上线。
在text-to-image(文生图)和image-edit(图像编辑)功能方面,nano-banana 展示了强大的能力,其性能被认为超越了 GPT-Image-1 模型。
该模型即将发布。

|
|
Google Whisk 扩展至77国并集成Veo 3 #5
谷歌AI工具Whisk扩展至77个新国家,并集成Veo 3模型,新增了将静态图像转换为八秒动画的功能。
Google Labs 宣布,其AI工具 Whisk 正在扩展至77个新的国家。同时,Whisk 迎来了重大功能升级,集成了 Veo 3 的能力。通过此次升级,用户现在可以将由 Whisk 生成的静态图像转换为时长八秒的动画片段。这些动画片段将具备增强的细节、真实感和音频效果。
为了鼓励创作,Google 宣布所有创作者每月都将获得5次免费的动画生成额度。

|
|
阿里云百炼上架Qwen-VL-Plus新版 #6
阿里云模型服务平台百炼上架了通义千问视觉语言模型Qwen-VL-Plus的新版本。
阿里云旗下模型即服务平台百炼(Bailian)近日上架了通义千问视觉语言模型Qwen-VL-Plus的新版本。
根据信息,此次上架的具体模型版本为“qwen-vl-plus-2025-08-15”。此前已经有更新过Qwen-VL-Max的新版本。
目前没有这些模型的发布公告,也暂不清楚Qwen是否会继续开源VL系列模型。
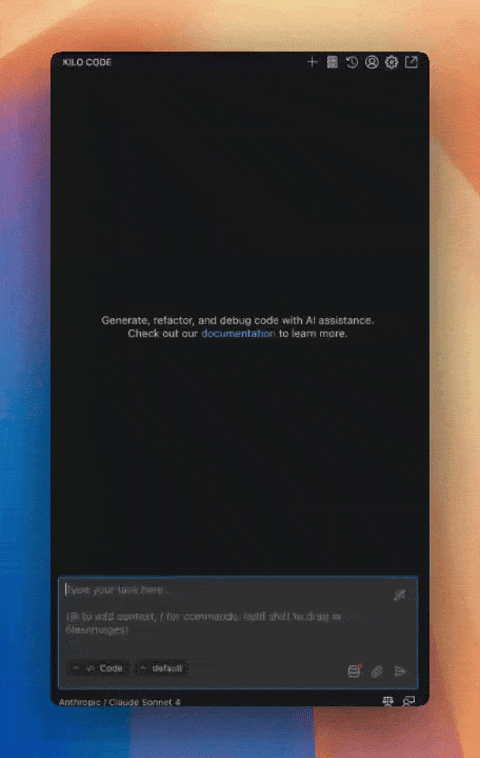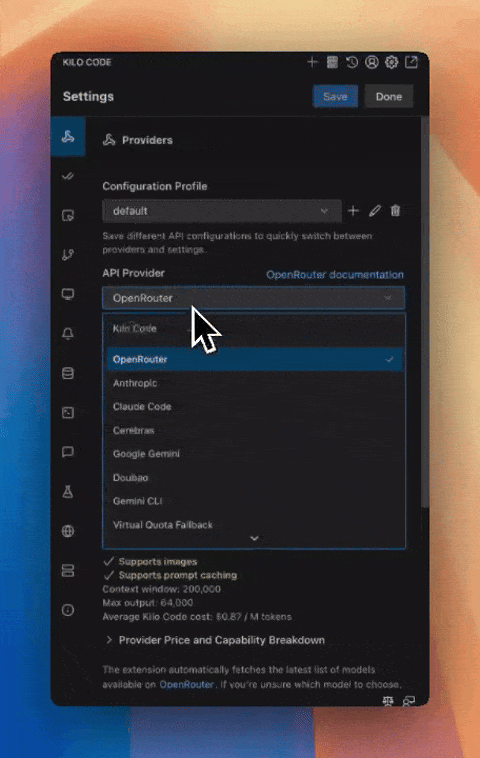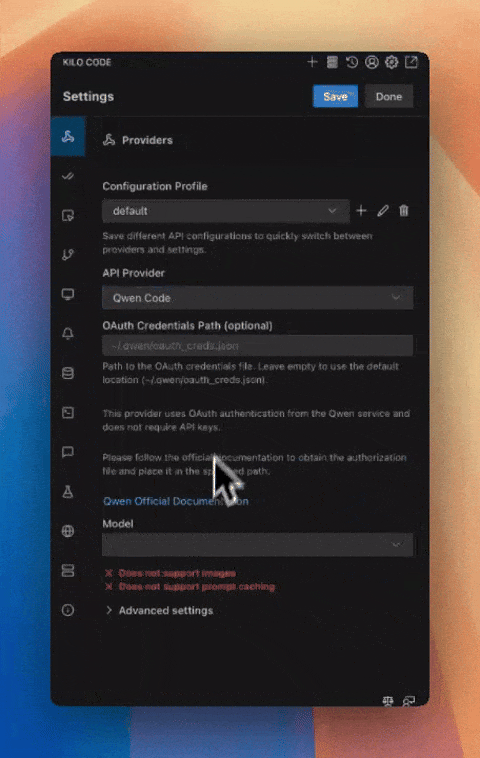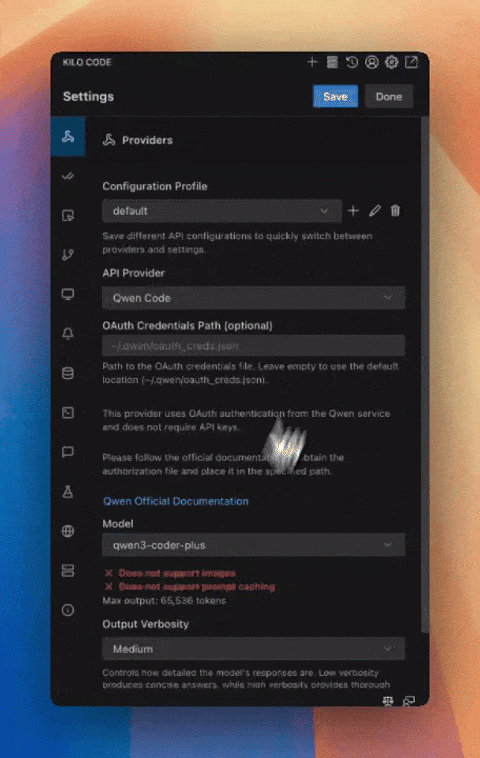
Kilo Code更新:新增基于用量的价格估算与QwenCode支持 #7
Kilo Code更新后,新增了基于真实用量的AI模型价格估算功能,并支持Qwen Code作为API provider。
Kilo Code近期发布重要更新。Kilo Code API provider现在能够根据真实世界的使用情况显示AI模型的价格估算。用户可以在设置中查看各模型的平均每百万token成本,该数据基于Kilo Code API provider每日处理的超过300亿token的真实用量,并已计入缓存折扣等因素。
此次更新增加了对Qwen Code作为API provider的支持。该集成可开箱即用,用户安装Qwen Code并创建账户后,Kilo Code能自动找到其配置文件。
|
|
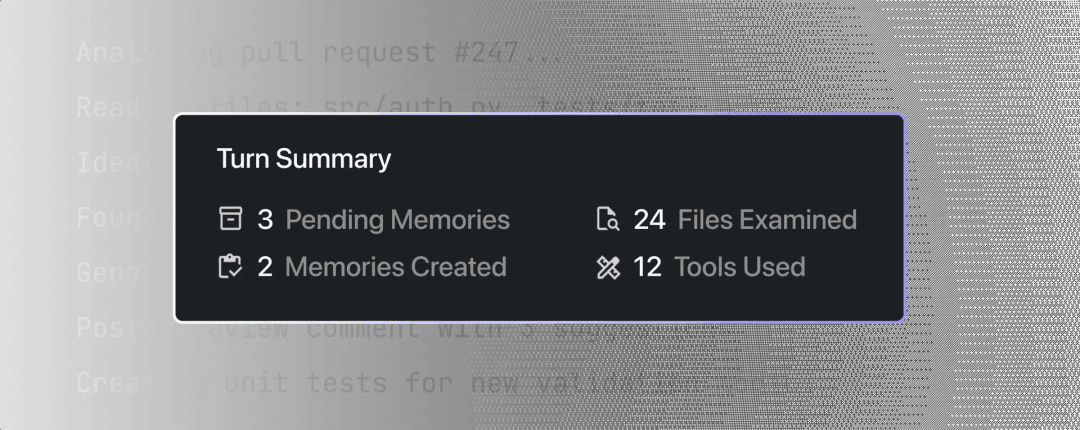
Augment Code推出Agent Turn Summary功能 #8
AI开发平台Augment Code推出Agent Turn Summary新功能,可将Agent的复杂操作序列浓缩为一行摘要,提升开发者效率。
AI软件开发平台Augment Code于8月19日发布了一项名为Agent Turn Summary的新功能。该功能可以将Agent在单次交互(turn)中执行的复杂操作序列浓缩为一行简洁的摘要,让开发者在几秒钟内就能掌握全局,而非花费数分钟滚动浏览大量日志。
该功能在Agent响应的末尾、反馈页脚旁边显示,内容包括工具调用的摘要与计数,以及所做更改的快照。用户可以一目了然地看到操作的整体范围,仅在需要时才展开查看完整细节。
目前,Agent Turn Summary功能已在VS Code和JetBrains的预发布版本中提供。
|
|
OpenAI在印度推出ChatGPT Go订阅服务 #9
OpenAI在印度市场推出名为ChatGPT Go的低成本订阅计划,每月定价399卢比,提供比免费版更高的使用额度。
OpenAI正式宣布在印度推出一项名为ChatGPT Go的全新低成本订阅计划。该订阅服务专为印度用户设计,定价为每月399卢比,约合4.55美元。
与免费版相比,ChatGPT Go提供了显著的权益提升,此外,该订阅服务支持通过UPI进行支付。
| 10倍 | |
| 10倍 | |
| 10倍 | |
| 2倍 |
OpenAI CEO Sam Altman表示,此举旨在首先在印度市场提供更实惠的ChatGPT服务。公司计划根据在印度的运营反馈,未来将此模式扩展到其他国家。

|
|
Microsoft Excel 推出 =COPILOT() 函数 #10
微软为Excel新增=COPILOT()函数,将大型语言模型的能力直接集成到电子表格单元格中,用于数据分析和内容生成。
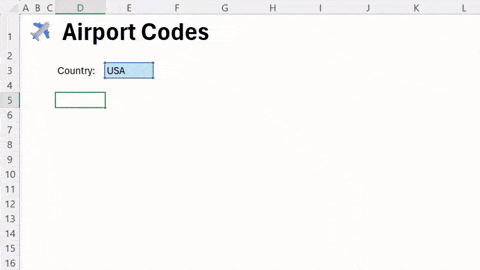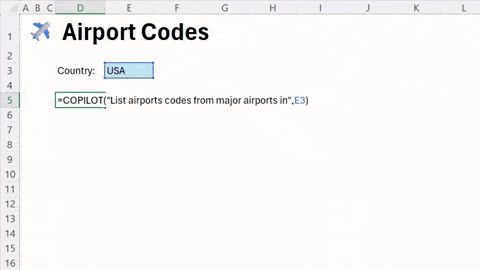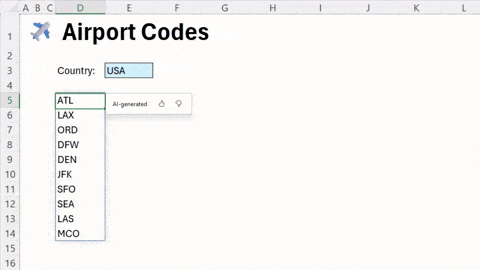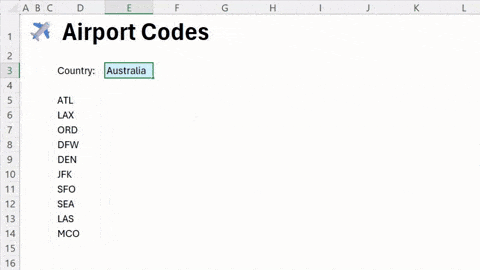
微软正在为 Excel 添加一项名为 =COPILOT() 的新函数,该功能将大型语言模型 (LLM) 的特性直接集成到电子表格的单元格中。
用户可以直接在网格内使用此函数来帮助填充单元格。根据指定的一组单元格数据,=COPILOT() 函数可以利用 AI 进行分析、生成内容和头脑风暴。具体功能包括生成摘要、标签、表格等。
该功能可能在部分地区无法使用。
|
|
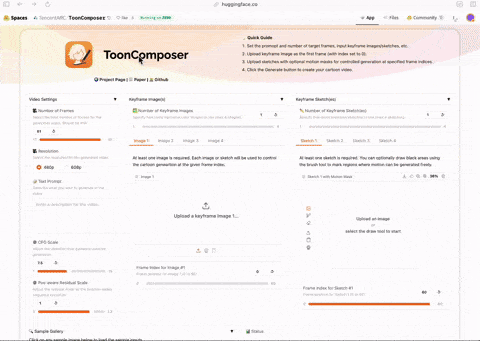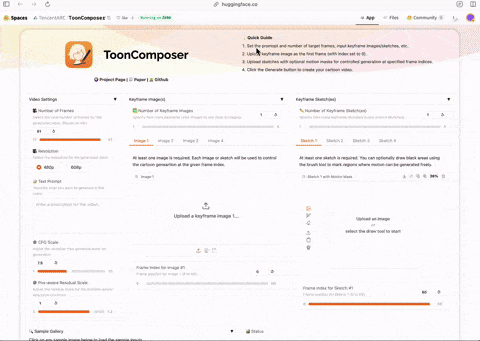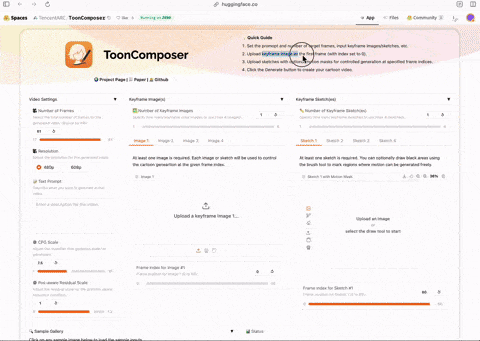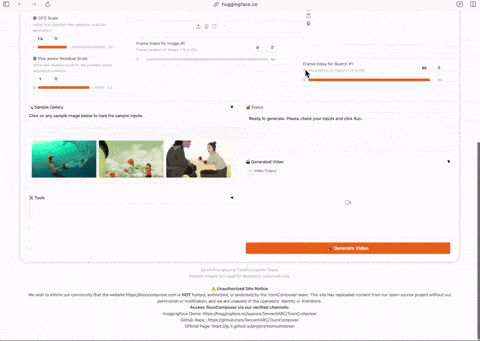
腾讯推出卡通制作工具ToonComposer #11
腾讯ARC团队发布了免费卡通制作工具ToonComposer,该工具能结合中间帧生成与上色,并可根据文本提示填充画面内容。
腾讯ARC团队发布了一款名为ToonComposer的卡通制作工具,现已在Hugging Face上免费提供。该工具旨在帮助用户高效地创作卡通动画。
ToonComposer的核心功能是将动画制作中的两个关键步骤——in-betweening(中间帧生成)与colorization (上色)相结合。用户只需提供基于线稿的关键帧和一个色彩参考帧,模型即可自动处理并生成完整的动画序列。
此外,该模型具备一项特殊功能,可以根据用户提供的文本提示(prompt),对草图或线稿中留白的区域进行想象和填充,从而丰富画面内容。据介绍,此模型基于阿里巴巴万相实验室(@Alibaba_Wan)的相关技术成果开发。
|
|
Firecrawl发布V2版本 #12
Firecrawl发布V2版本并宣布完成1450万美元A轮融资,新版本将网页抓取速度提升10倍并增加了语义爬取等新功能。
Firecrawl宣布推出其V2版本,并同时公布已完成由Nexus Venture Partners领投的1450万美元A轮 融资。官方称此次更新是其迄今为止最大规模的发布。
FirecrawlV2的核心升级在于性能和功能的扩展,旨在让agent能够更高效地爬取互联网信息。新版本将网页抓取(scraping)速度提升了10倍。此外,V2引入了多项新功能,包括Semantic crawling (语义爬取)以及新闻和图片搜索功能,进一步增强了其数据获取和处理能力。

|
|
Allen Institute for AI 发布 OLMo 2 1B 早期训练检查点 #13
Allen Institute for AI发布了OLMo 2 1B模型从训练第0步到第37000步的早期检查点,以帮助社区研究LLM能力的涌现过程。
Allen Institute for AI (AI2) 近日发布了 OLMo 2 1B 模型的早期训练检查点集合。
这些检查点是在官方 OLMo 2 1B 模型原始训练完成后生成的。从训练的第0步开始,每隔1000步 保存一个检查点,直至第37000步。
旨在帮助研究社区深入探究大型语言模型(LLM)的能力是如何在训练中逐步涌现的。研究人员可以利用这些检查点进行分析、复现和比较,以更好地理解模型的发展过程。
|
|
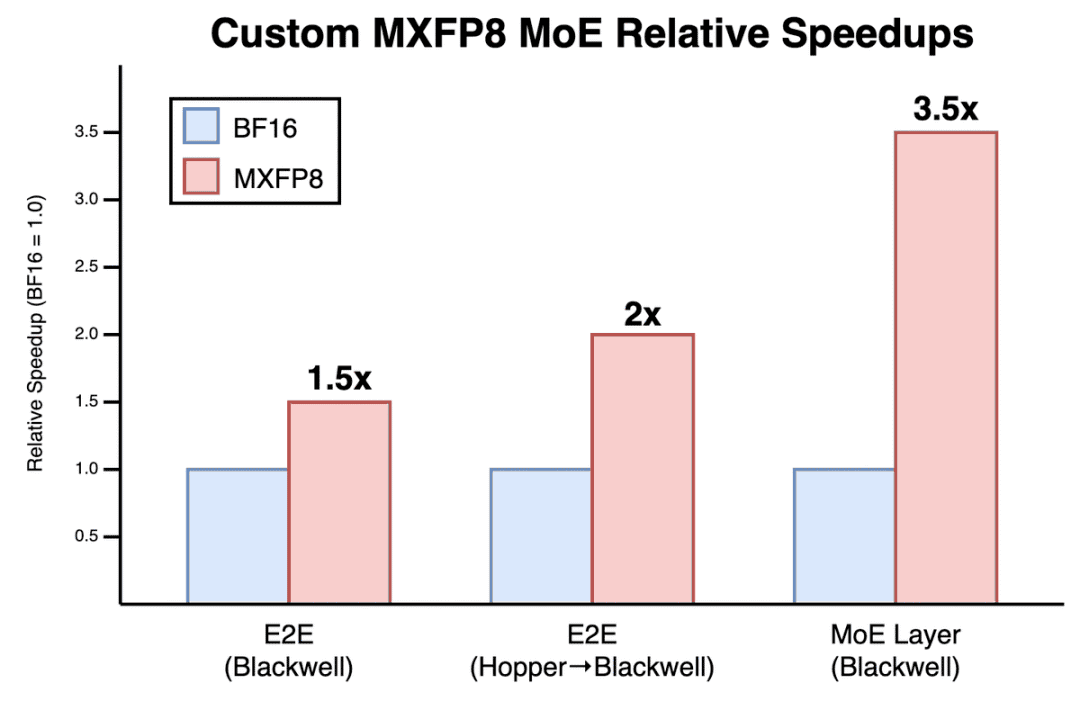
Cursor发布全球最快MXFP8 MoE内核 #14
Cursor团队通过重建内核并使用MXFP8格式,成功将MoE层训练速度提升3.5倍,实现了1.5倍的端到端训练总速度提升。
为解决MoE层在训练中速度过慢的问题,Cursor团队在内核级别对其进行了完全重建,并转向使用MXFP8 格式。
在训练其编程模型时,MoE层曾占据了27%至53%的训练时间。经过优化后,新的MXFP8 MoE内核实现了MoE层速度提升3.5倍,并带来了1.5倍的端到端训练总速度提升。该团队称,这是目前全球最快的MXFP8 MoE 内核。
|
|
苹果Xcode 26将原生集成Claude模型 #15
苹果将在Xcode 26中原生集成Anthropic的Claude大模型,为开发者提供除ChatGPT 外的又一AI代码助手选择。
苹果公司正在扩展其集成开发环境Xcode 26的AI代码助手生态,将在原生支持OpenAI的ChatGPT 之外,新增对Anthropic****Claude大模型的原生集成。 根据Xcode 26 Beta 7版本的实测信息,开发者将可以直接在Xcode中登录Claude账户,并调用包括今年5月发布的Claude Sonnet 4.0和Claude Opus 4在内的模型。这一变化意味着开发者无需再像以往那样手动配置API,即可直接在Xcode内利用Claude进行代码生成、优化和辅助编程,为开发者提供了ChatGPT 之外的替代选项。
|
|
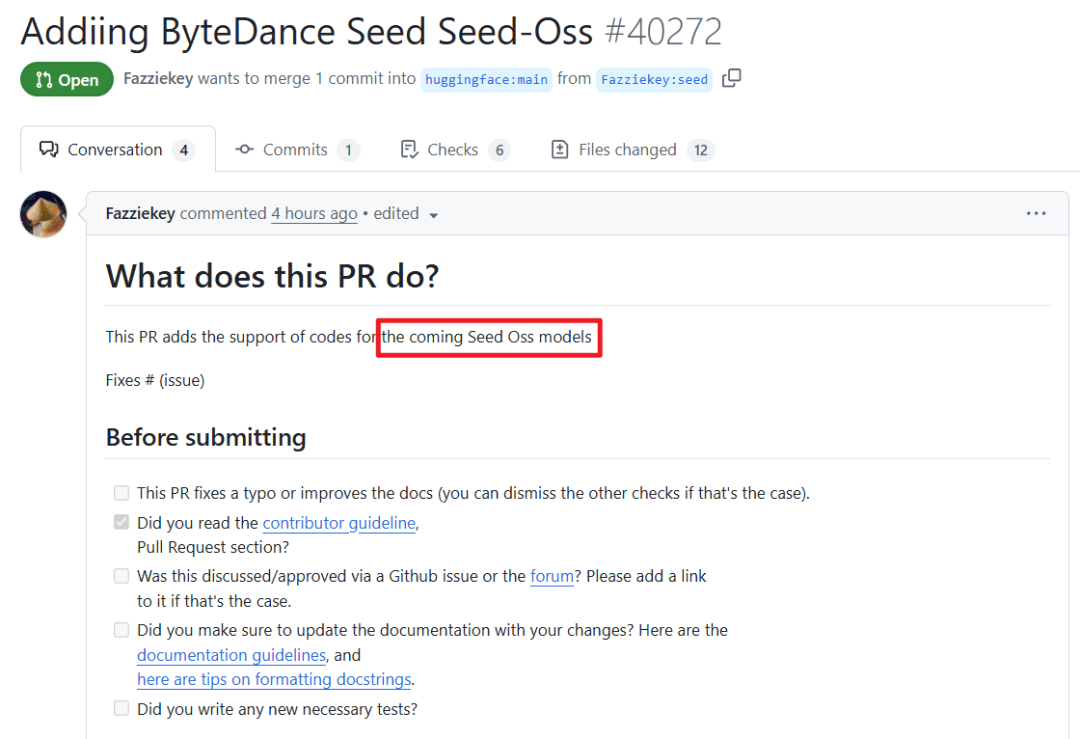
字节跳动即将发布开源模型SeedOss-36B #16
根据Hugging Face Transformers库的信息,字节跳动即将发布一款名为SeedOss-36B的360亿 参数稠密开源模型。
字节跳动即将发布一款名为SeedOss-36B的开源模型。相关信息来源于Hugging Face Transformers 库中的一个Pull Request。
该Pull Request由GitHub用户“Fazziekey”提交,标题为“Addiing ByteDance Seed Seed-Oss ”,旨在为即将推出的Seed Oss模型添加代码支持。
从目前披露的信息来看,SeedOss-36B很可能是一个360亿参数的稠密模型,而非MoE(Mixture-of-Experts )架构。
|
|
字节跳动研发AI手机 #17
据报道,字节跳动正与中兴合作研发一款暂定名为“豆包手机”的AI手机,预计将于今年底或明年初推出,初期仅供内部测试。
据晚点科技报道,字节跳动正在研发一款AI手机,暂定名称为“豆包手机”。该项目由字节跳动 与中兴合作进行,其中字节负责大模型功能及部分操作系统相关工作,而硬件的设计与生产则主要由中兴作为ODM承担。
该产品由字节跳动负责AI硬件的Ocean团队主导研发。Ocean团队负责人为Kayden,他直接向Flow业务负责人朱骏(Alex Zhu)汇报。该团队整合了字节跳动历年来收购的多个硬件产品团队,包括锤子手机、VR头显PICO、智能耳机Ola Dance等,同时还吸纳了去年从荣耀加入的手机研发人员。除了手机项目,Ocean团队还在探索多款AI设备,例如去年已上市发售的Ola Friend 智能耳机以及AI眼镜等。
根据计划,这款“豆包手机”预计将于今年年底或明年年初推出。在早期阶段,该设备将主要用于字节内部团队的测试,目前暂时没有对外公开发售的计划。
|
|
英伟达为中国开发两款Blackwell架构AI芯片 #18
英伟达正为中国市场开发两款基于Blackwell架构的AI芯片B30A和RTX6000D,其性能将优于当前获准销售的H20芯片。
据报道,英伟达正在为中国市场开发两款基于其最新Blackwell架构的新型AI芯片,其性能将强于当前获准在中国销售的H20芯片。
其中一款芯片暂定名为B30A,采用单芯片设计,其原始算力约为旗舰产品B300的一半。该芯片配备高宽带内存与NVLink技术,性能优于H20。目前该芯片的规格尚未完全确定,但英伟达计划最快于下月向中国 客户交付样品进行测试。 另一款专为中国市场设计的芯片于今年5月被报道,暂定名为RTX6000D。该芯片主要用于AI推理任务,售价将低于H20。它采用传统的GDDR显存,内存带宽为每秒1398GB,略低于美国政府今年4月新规设定的1.4TB/s限制阈值。预计首批小批量交付将在9月进行。
英伟达方面表示,其产品符合政府的要求,且所有产品均已获得相关部门批准并用于商业用途。
|
|
谷歌宣布首座AI数据中心核反应堆所在地 #19
谷歌宣布其首座用于AI数据中心供电的小型模块化核反应堆将建在美国田纳西州的橡树岭 。
谷歌公司宣布,其首座用于为AI数据中心供电的模块化核反应堆将选址于美国田纳西州 的橡树岭 。
该项目旨在利用多个小型模块化核反应堆,为日益增长的AI计算需求提供稳定电力。这些核反应堆由Kairos Power公司负责研发和建造。根据计划,目前每个反应堆可以提供50兆瓦的电力供应。Kairos Power 的目标是到2035年,为谷歌提供总计500兆瓦的电力。
|
|
Meta 正式宣布重组AI部门 #20
Meta正式宣布重组其AI部门,新组织命名为Meta Superintelligence Labs (MSL),下设四个专注于基础模型、研究、产品和基础设施的团队。
Meta已通过一份内部备忘录正式宣布对其AI部门进行重组。
新的AI组织被命名为Meta Superintelligence Labs(MSL),其核心是一个名为TBD Labs 的新团队。TBD Labs将专注于基础模型,如今年4月发布最新版本的Llama系列。其余三个团队将分别专注于研究、产品集成和基础设施。
|
|
提示:内容由AI辅助创作,可能存在幻觉和错误。