
核心内容点:
- 读写分离通过将读操作路由到从库、写操作路由到主库,有效解决高并发场景下的数据库性能瓶颈。
- go-zero框架通过配置文件和上下文管理器实现简单灵活的读写分离,支持轮询/随机负载均衡策略。
- 重点介绍强制主库读取(强一致性场景)、事务处理、故障转移等关键实现细节和最佳实践。
源自 | kevwan微服务实践 2025-07-15 09:29
在高并发的现代应用中,数据库往往成为系统的瓶颈。读写分离作为一种有效的数据库优化策略,能够显著提升系统的性能和可用性。本文将深入讲解读写分离的核心概念、实现原理,并通过go-zero框架提供详细的实战示例。
1. 读写分离的使用场景和必要性
1.1 什么是读写分离
读写分离是一种数据库架构模式,它将数据库操作分为两类:
-
• 写操作:INSERT、UPDATE、DELETE等修改数据的操作,路由到主库(Master)
-
• 读操作(强一致性要求):SELECT查询操作,路由到主库(Master)
-
• 读操作(非强一致性要求):SELECT查询操作,路由到从库(Replica/Slave)
1.2 核心使用场景
高读写比例的应用
大多数 Web 应用的 DB 操作都是读多写少,典型场景包括:
-
• 电商平台:商品浏览远多于下单操作
-
• 内容平台:文章阅读远多于发布操作
-
• 社交媒体:内容消费远多于内容创建
-
• 新闻网站:新闻浏览远多于新闻发布
数据库负载分担需求
-
• 主库压力过大:单一数据库无法承受高并发访问
-
• 读写操作互相影响:大量读操作影响写操作性能
-
• 资源利用不均:数据库服务器资源未充分利用
1.3 读写分离的必要性
性能提升
-
• 传统单库模式:
-
• 读写操作 → 主库 (100%负载)
-
• 读写分离模式:
-
• 写操作 → 主库 (小负载,但无法横向扩容)
-
• 读操作 → 从库 (大负载,但可以分散到多个从库)
可用性增强
-
• 故障隔离:读操作故障不影响写操作
-
• 负载均衡:多个从库分担读取压力
-
• 灾备能力:从库可作为备份数据源
扩展性提升
-
• 水平扩展:可通过增加从库处理更多读请求
-
• 成本效益:从库可使用较低配置的硬件
-
• 维护便利:可在从库上进行复杂查询和报表生成
2. 读写分离的实现原理
2.1 整体架构
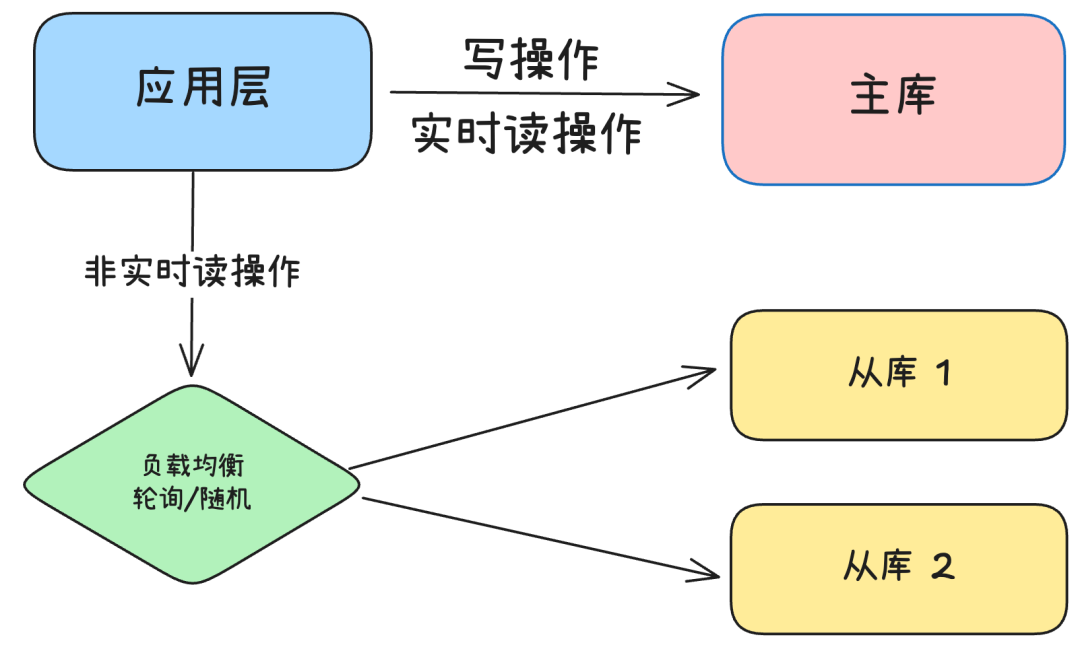
2.2 核心组件
连接路由器 (Connection Router)
负责根据SQL操作类型决定使用哪个数据库连接:
-
• 根据上下文模式选择连接
-
• 管理连接池和负载均衡
负载均衡器 (Load Balancer)
在多个从库之间分配读请求:
-
• 轮询策略:按顺序依次访问从库
-
• 随机策略:随机选择从库
上下文管理器 (Context Manager)
通过上下文传递读写模式信息:
-
• 显式指定读主库场景
-
• 显式指定读从库场景
-
• 写操作强制使用主库
2.3 数据一致性处理
最终一致性
-
• 主从同步存在延迟(通常几毫秒到几秒)
-
• 适用于对数据实时性要求不严格的场景
强一致性需求处理
|
|
3. 使用go-zero读写分离的示例
3.1 配置读写分离
配置文件设置
|
|
配置结构体定义
|
|
3.2 初始化数据库连接
|
|
3.3 模型层实现
|
|
3.4 服务层最佳实践
|
|
3.6 监控和调试
|
|
4. 故障转移
|
|
5. 总结
读写分离是提升数据库性能的重要手段,go-zero框架提供了优雅的读写分离实现:
5.1 核心优势
-
• 简单配置:通过配置文件即可启用读写分离
-
• 自动路由:框架自动识别读写操作并路由到合适的数据库
-
• 灵活控制:支持通过上下文强制指定读写模式
-
• 负载均衡:支持轮询和随机负载均衡策略
5.2 使用建议
- 合理配置从库数量:根据读写比例确定从库数量
- 监控主从延迟:确保业务可接受的数据延迟
- 选择合适的负载均衡策略:根据从库性能选择轮询或随机
- 处理数据一致性:在需要强一致性的场景使用主库读取
通过合理的读写分离配置和使用,可以显著提升系统的并发处理能力和整体性能。
项目地址
https://github.com/zeromicro/go-zero
欢迎使用 go-zero 并 star 支持我们!