
核心内容:
- 多元素整合:通过标签引用实现多图融合,突破平台上传限制并提升人脸光影一致性
- 红框标注技术:用于元素提取、区域替换和动作漫画生成,配合PPT与手机编辑工具实现高效操作
- AR场景构建:基于现实建筑图生成位置感知的增强现实体验,支持兴趣点标注与场景交互设计 源自 | AI沃茨卡尔的AI沃茨 2025-08-28 19:55
来不及解释了,
一致性的王Nano banana已经上线到AI Studio、Gemini、Whisk、Opal、OpenRouter,在flowith还可以批量生成,不用在lmarena上无尽抽卡了,这些平台的使用方法留到后面,先肝13种邪修玩法,照例是带提示语和效果展示。

原来以为插画转手办已经是巅峰了,没想到才是开头,一晚上加上午啥都没干,光坐在电脑前生图了,量大管饱!Here we go!

PS:下面的玩法来自于歸藏、-ZHO-、Bilawal Sidhu、Travis Davids、yachimat、海拉鲁编程客、Simon、AiOLDX等的超级脑洞,感谢各位!果然用Nano Banana来修改背景、修改图片画风、修改人物身上的配件、发型、衣服,人脸等这些都太太太太太常规了!!!
所有玩法我们都打包放在文档里了,公众号回复“香蕉“就OK。
开局先来个多元素合并成图,gemini一次只能上传10张图,除掉一张背景,理论上最多只能指定9个元素。但是如果将所有内容整合到一张图片中并加上标签,输入提示词时候用标签来引用的话,就可以摆脱上传数量的限制了。
这样做还有一个好处就是融合的时候人脸的光影和颜色一致性会更好。
在一个美术馆或博物馆里,红色的墙壁上挂着古典的肖像画作。画面的中心是一个大理石柱基座,但基座上展示的并非传统雕塑,而是一根用胶带贴着的普通香蕉。围绕着这个“香蕉艺术品”,站着mona、pearl、david、van gogogh、leonardo

但测试下来不标注文字也可以起作用,
A model is posing and leaning against a pink bmw. She is wearing the following items, the scene is against a light grey background. The green alien is a keychain and it’s attached to the pink handbag. The model also has a pink parrot on her shoulder. There is a pug sitting next to her wearing a pink collar and gold headphones.

打标的话我是直接把图片导入ppt上插入文字框,中间也想过用Nano Banana偷懒,但是它标注的图片会有遗漏,或者是文字和图片对不上的情况。

另外一个高级玩法就是 红框,简单来说就是框出图片中的元素,基于这个元素可以提取,放大,替换,独立成片。
将红色盒子里的人分开,变成高清单人照片



除了放大,红框还可以限定物体更换的区域,这样做的好处是因为每张图大小不同,有的时候模型会误解插入物体应有的大小。

如果把红框涂满转成大面积的红色蒙版,还可以做无中生有。
replace the brush area with a chanel bag




红框框照样是可以拖到ppt里完成,蒙版就更好做了,用手机自带的图片编辑就可以完成。
那如果还想简单一些,或者说利用模型脑子里的世界知识呢?
将照片转换为自上而下的视图并标记摄影师的位置。
画出红色箭头看到的东西
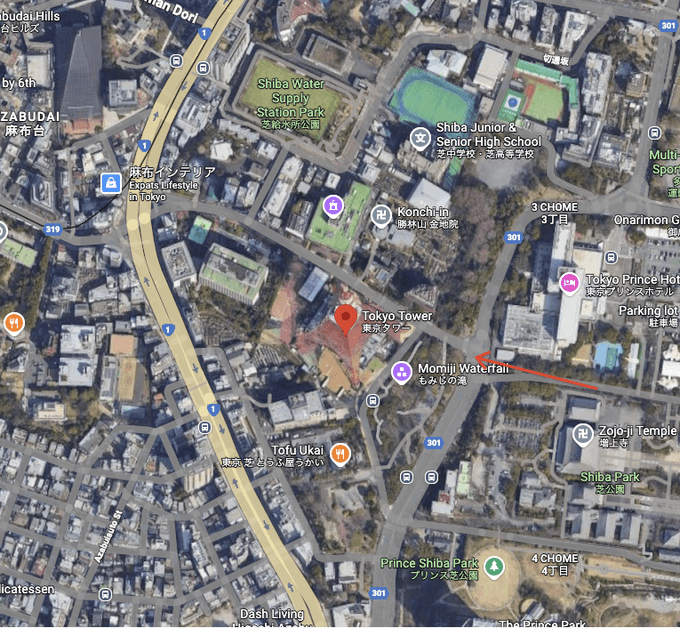

在这个基础上还可以用veo3生成视频空镜素材,

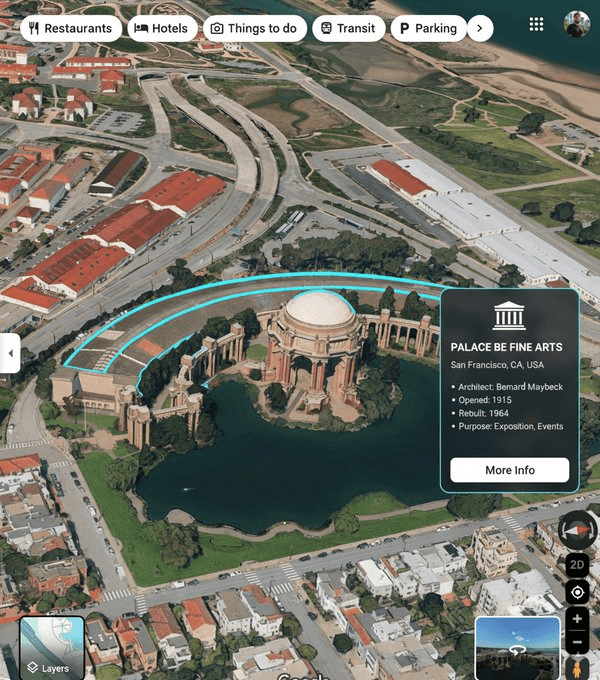
还有还有,Nano Banana 拥有 Gemini同款的世界知识,我们还可以上传各种现实世界的建筑图进行标注。
你是一个基于位置的AR体验生成器。在图片中突出显示[兴趣点],并为它添加相关的信息注释。


如果多画几笔红线,画成火柴人的话,还可以做成大幅度动作漫画!
The characters in Figure 1 and Figure 2 should be used to generate a complete picture based on the action in Figure3. The entire picture should be coordinated, and then the original actions should be removed. For example, this little red figure and the little man should be removed, leaving only the characters’ actions.
让这两个角色使用图 3 中的姿势进行战斗,添加适当的视觉背景和场景交互,生成的图像比例为 16:9



插画变手办变多了,还可以让Nano Banana来个插画变真人,看看会不会有AI假感。
Generate a photo of a girl cosplaying this illustration, with the background set at Comiket


那如果想要自己捏一个原创角色呢?也可以为我生成人物的角色设定(Character Design)
比例设定(不同身高对比、头身比等)三视图(正面、侧面、背面)
表情设定(Expression Sheet) → 就是你发的那种图
动作设定(Pose Sheet) → 各种常见姿势
服装设定(Costume Design)



那我们再试试看做一个带人物的海报,看看Nano Banana的文字保持能力,
1)把里面的产品换成 iPhone 文字也换成 相应的苹果广告语
2)人物也换成女生,配色换成粉色,四个大字也换成苹果的广告语
🙋我是雨琦粉丝,我是雨琦粉丝



而且用Nano Banana做点纯文字的概念解释图也是可以的,就是感觉画风没那么好看
请仔细阅读输入的内容,提取主题和核心要点,生成反应文章内容的封面图,要求:
- 信息图,可以适当添加文字,默认使用英文
- 加上丰富可爱的卡通人物和元素
- 图片尺寸为横版(16:9)
- 先思考后再生成
解释GPT5是什么

解释AI coding和人工codng的区别
写在最后
可惜的是Nano Banana目前有点听不懂对图片尺寸限定的话,16:9,1:1,4:3这些一个都听不懂。
不然就更没PS的事了,但不知道是不是我的打开方式不对,Nano Banana上线了Gemini和AI Studio之后成功率反而还没有在Lmarena上高,上面的案例我基本都是gemini和ai studio交叉着用,平均跑了5-6次才成功。

继GPT4o之后,我已经很久没有那么高频用一个模型了,所以看到那么多好玩的邪修用法我觉得太需要来一个大收集了。
最后的最后,贴上一大堆使用链接,哪里不会点哪里
🔗 gemini.google.com/app
🔗 labs.google/fx/tools/whisk/project
🔗 opal.withgoogle.com/?mode=canvas
🔗 openrouter.ai/chat?models=google/gemini-2.5-flash-image-preview:free
🔗 aistudio.google.com/app/prompts/new_chat?model=gemini-2.5-flash-image-preview