Source | Muluo Alibaba Cloud Developer 2025-04-21 08:30

The article discusses the development trend of AI Agents and demonstrates how to develop a question answering system that supports private knowledge bases based on MCP (Model Context Protocol) through a practical case.
Preface
Industry speculation suggests that 2025 will be the first year of AI Agents. Judging from the current speed of technological development, this trend is indeed emerging. Starting with the explosive popularity of DeepSeek at the beginning of the year, the capabilities of open-source large models are now basically on par with or even surpass those of commercial large models. The completely open-source strategy has thoroughly democratized the use of large models. This can be said to have changed the business model of AI applications to some extent. The advantages of closed-source models based on self-training have been significantly weakened, and commercial competition has shifted from model performance to innovation in application scenarios.
The forms of AI applications are constantly evolving, from early Chat to RAG, and now to Agent. Referring to the technological development of the Web 2.0 and mobile internet eras, when the development demand for a new form of application grows explosively, it will drive the establishment of new development frameworks and new standards. AI applications are undergoing this process.
Currently, development frameworks are still in a state of diversification. Whether Python will become the mainstream development language and which development framework will become mainstream are still unknown and remain to be seen. However, the recently popular MCP (Model Context Protocol) seems to have become a de facto standard, especially with OpenAI’s recent official announcement of support for MCP.
The introduction of MCP will not be detailed in this article. With the aim of learning, a practice was carried out, mainly to experience how to develop an Agent application based on MCP. This practice will implement one of the most common types of AI applications, namely a question answering system, which supports question answering based on private knowledge bases, and will optimize knowledge base construction and RAG.
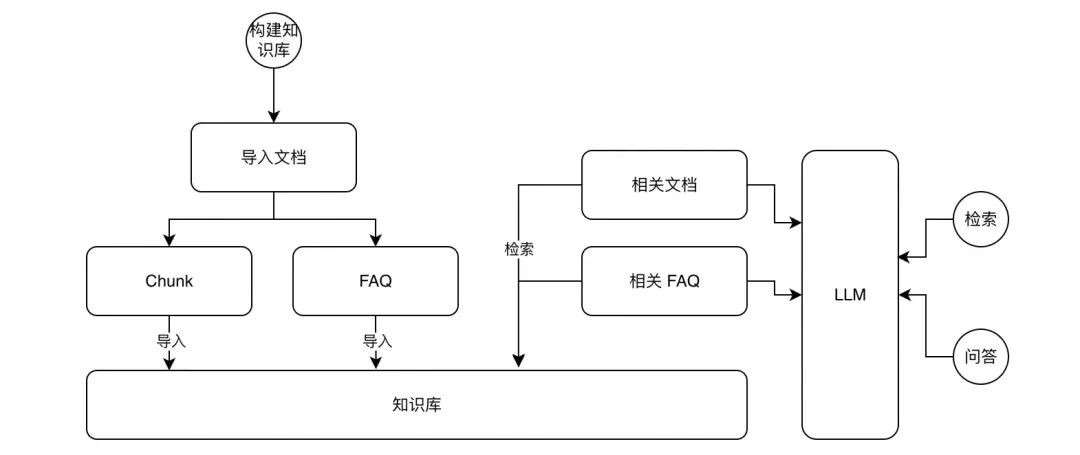
Overall Process Design

It is mainly divided into two parts: knowledge base construction and retrieval.
- Knowledge Base Construction
a. Text Segmentation: Segment the text, and the segmented content needs to ensure text integrity and semantic integrity.
b. Extract FAQs: Extract FAQs based on the text content as a supplement to knowledge base retrieval to improve retrieval effectiveness.
c. Import Knowledge Base: Import the text and FAQs into the knowledge base, and import the vectors after Embedding.
- Knowledge Retrieval (RAG)
a. Question Decomposition: Decompose and rewrite the input question into more atomic sub-questions.
b. Retrieval: Retrieve relevant texts and FAQs for each sub-question separately. Vector retrieval is used for texts, and full-text and vector hybrid retrieval is used for FAQs.
c. Knowledge Base Content Screening: Screen the retrieved content and retain the content most relevant to the question for reference answers.
Compared with the traditional Naive RAG, some common optimizations have been made in knowledge base construction and retrieval, including Chunk segmentation optimization, FAQ extraction, Query Rewrite, hybrid retrieval, etc.
Agent Architecture
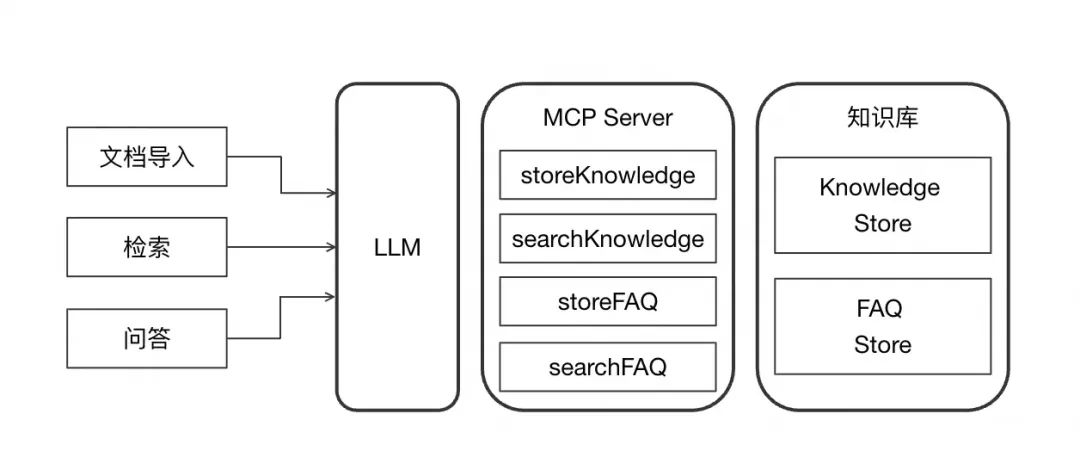
The overall architecture is divided into three parts:
-
Knowledge Base: Internally contains Knowledge Store and FAQ Store, which store text content and FAQ content respectively, and support hybrid retrieval of vectors and full text.
-
MCP Server: Provides read and write operations for Knowledge Store and FAQ Store, providing a total of 4 Tools.
-
Function Implementation Part: The import, retrieval, and question answering functions of the knowledge base are completely implemented through Prompt + LLM.
Specific Implementation
All the code is open source here, divided into two parts:
-
Client-side implemented in Python: Implements the basic capabilities of interacting with large models, obtaining Tools through the MCP Client, and calling Tools based on feedback from large models. The three main functions of knowledge base construction, retrieval, and question answering are implemented through Prompt.
-
Server-side implemented in Java: Implements the MCP Server based on the Spring AI framework. Since the underlying storage uses Tablestore, the main framework is based on the code in this article for transformation.
Knowledge Base Storage
Tablestore (Vector Search Function Introduction) is selected for knowledge base storage, mainly for the following reasons:
-
Simple and easy to use: You can start using it after only one step of creating an instance. The Serverless mode eliminates the need to manage capacity and subsequent operation and maintenance.
-
Low cost: Completely pay-as-you-go, automatically scales horizontally according to the storage scale, and can be scaled up to PB level. Of course, if a local knowledge base is used, the cost is definitely zero, but what is implemented here is an enterprise-level, cloud-shared knowledge base.
-
Complete functions: Supports full-text, vector, and scalar retrieval functions, and supports hybrid retrieval.
MCP Server
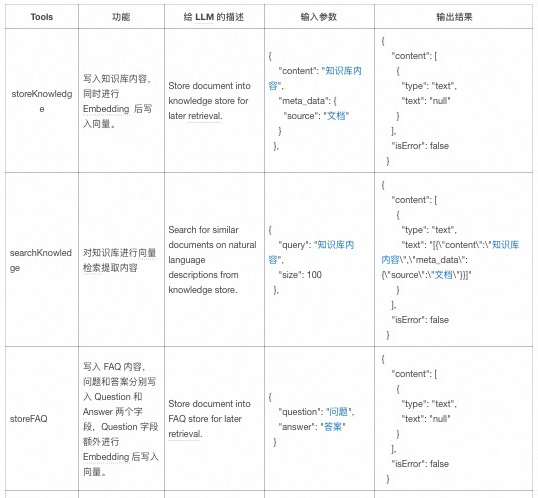
Implements 4 Tools (refer to TablestoreMcp for specific registration code), with the following descriptions:

Knowledge Base Construction
- Segment the text and extract FAQs
It is completely completed through prompts, which can be optimized according to your own requirements.



The above is an example. It can be seen that the large model can accurately segment the text and extract FAQs. The advantage of this method is that the segmented text can ensure integrity and semantic consistency, and can flexibly process the format. The extracted FAQs are very comprehensive, and answering simple questions by directly searching FAQs is the most accurate and direct. The biggest disadvantage is that the execution is slow and the cost is high, and a large number of Tokens will be consumed at one time, but fortunately it is a one-time investment.
- Write to the knowledge base and FAQ library
This step is also completed through prompts. Based on the MCP architecture, it can be easily implemented. An example is as follows:

Knowledge Base Retrieval
Similarly, this step is also implemented through prompts and MCP, which is very simple. An example is as follows:
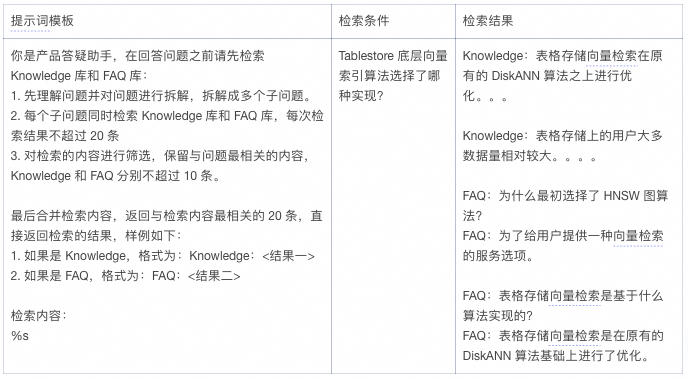
A slightly more complex retrieval is implemented through prompt word description:
-
First decompose the problem into more atomic sub-problems.
-
Each sub-problem retrieves the knowledge base and FAQs respectively, and after summarizing the retrieval results, filters and leaves the content most relevant to the problem.
-
Return the results according to the format.
Knowledge Base Question Answering
Directly look at the prompt words and effects

From the Log in the MCP Server, you can see that the knowledge base and FAQ retrieval tools are automatically called, and can answer according to the previously imported content.
Demonstration
1. Create a knowledge base storage instance
You can create a Tablestore instance through the command line tool ( Download address ), refer to This document to configure first.
After the configuration is successful, execute the following command to create an instance. The instance name is selected by yourself and needs to be unique within the Region.

2. Start MCP Server
Before starting, you need to configure the following parameters in the environment variables:
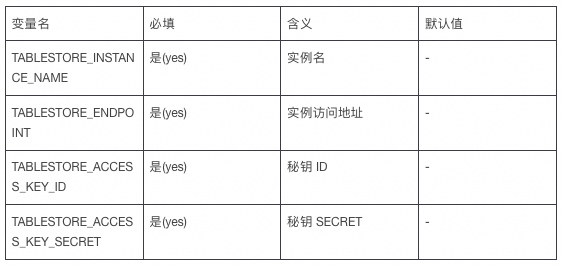
You can refer to the steps in the code base README to start, or you can import the project into the IDE and run the App class directly. The table and index will be automatically initialized after starting.
3. Import knowledge base
This step requires executing the knowledge_manager.py tool in the code base. Before execution, you need to configure the API-KEY for accessing the large model. The default is qwen-max.
|
|
Please prepare the knowledge base document yourself, use markdown format, and execute as follows:

4. Retrieve knowledge base
Execute as follows:

5. Question answering based on knowledge base

Last
Corresponding to the viewpoint in the preface, this round of technological revolution can refer to the technological development of the Web 2.0 and mobile internet era. When the development demand for a new form of application grows explosively, it will definitely drive the establishment of new development frameworks and new standards. The technology of AI applications can be completely built on the current technology framework, so the speed of development and iteration is very fast, and I look forward to future development.
Building an OLAP full scenario, revealing the integrated architecture of real-time/offline data warehouse
With the continuous increase of enterprise business data volume and data sources, the difficulty and complexity of analysis have increased significantly. AnalyticDB MySQL provides a data analysis platform that can integrate multiple types of data sources, ensure data consistency and integrity, and efficiently analyze data. It supports complex query and analysis needs, can quickly gain insight into data value, and better support business decisions.