- 模型对比实测:GLM-5.2、Kimi 2.7 Code 与 Claude Opus 4.8 在复杂单文件 Excel 分析工具开发任务中的表现差异显著。
- Opus 4.8 意外垫底:公认跑分最高的 Opus 4.8 因严重遗漏搜索、分页、中文分析报告等核心指令,仅交付功能残缺的半成品。
- 长程任务关键能力:真实工程任务中,模型对复杂长提示的指令服从度与抗“代码惰性”能力,比理论跑分更决定实际可用性。
源自 | 郭震AI
最近GLM-5.2,Kimi 2.7 Code,两个新模型发布,与当前最强模型Claude Opus 4.8,对比实测下,感兴趣的可以看下。
新模型介绍
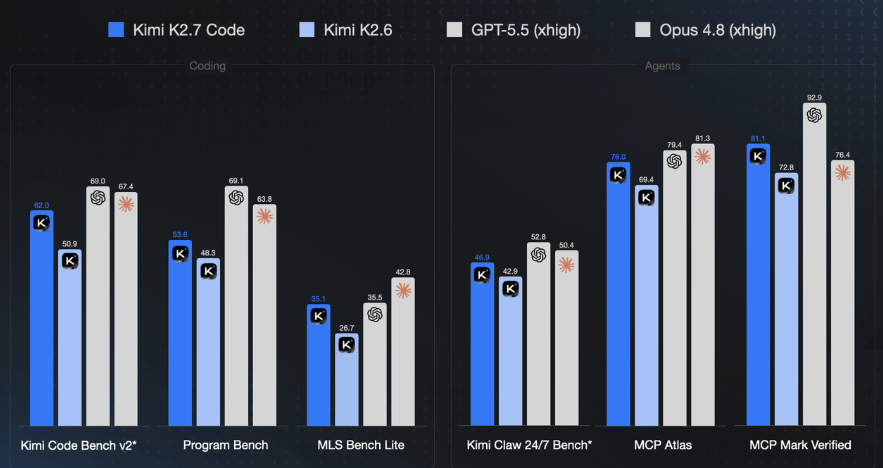
GLM5.2,在以下两个数据集,都仅次于 Opus 4.8:
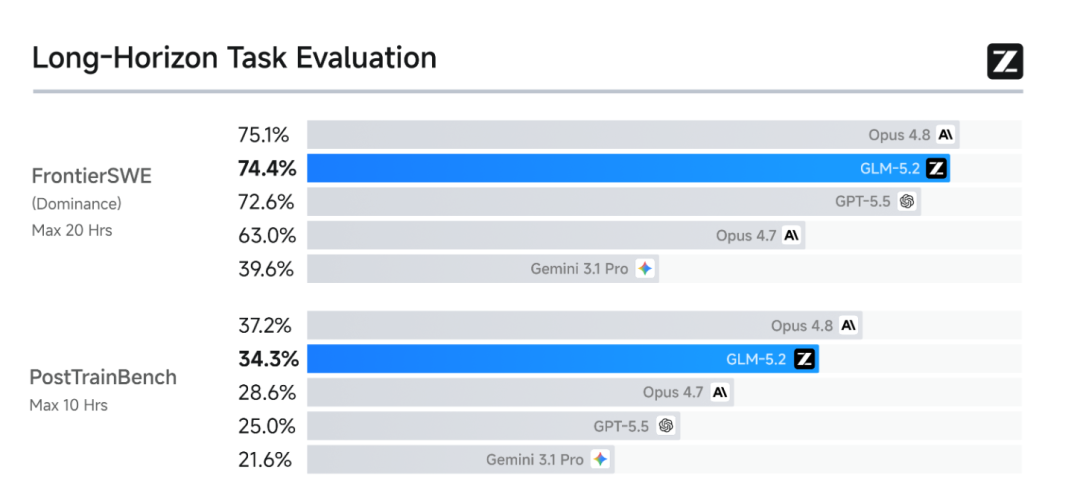
FrontierSWE,这个数据集最有意思,
它主要看模型能不能在真实代码工程里完成非常难、开放式、长时间的技术任务,
很多任务需要跑 20 小时,
所以它真实考察了模型长程任务处理能力,这也是我最喜欢的,因为开发软件就是需要这样的能力强。
Kimi 2.7 Code,也在最新发布,它同样把考察长程任务作为第一优先级,就是左一柱状图:

看到它同样接近Opus 4.8 xhigh模式
模型胜任长程任务、开发复杂项目,看来都是大模型迭代的方向。
接下来咱们就重点测试它们三个处理相对复杂任务能力,到底实际使用表现如何。
接下来直接开始测评
对比实测
测评思路:使用一个典型的中小型Agent任务,测评大家普遍关心的智能体能力。
然后选择Gemini-3.1-Pro为裁判,根据裁判的打分,给出客观的结果评估。
Agent任务,提示词如下:
开发一个单文件 HTML 网页,实现 Excel 数据分析与可视化工具。 支持上传 .xlsx/.xls,使用 SheetJS 解析 Excel,读取多 Sheet,并展示可搜索、分页、横向滚动的数据表格。 自动识别字段类型、统计行列数、缺失值、唯一值、最大/最小/平均/求和,并生成中文数据分析报告。 使用 ECharts 自动生成柱状图、折线图、饼图、散点图等可视化,并支持用户选择 X/Y 字段和图表类型自定义生成。 只输出完整可运行的单文件 HTML 代码,不要解释,不要 Markdown,不依赖后端。
先发给GLM-5.2:
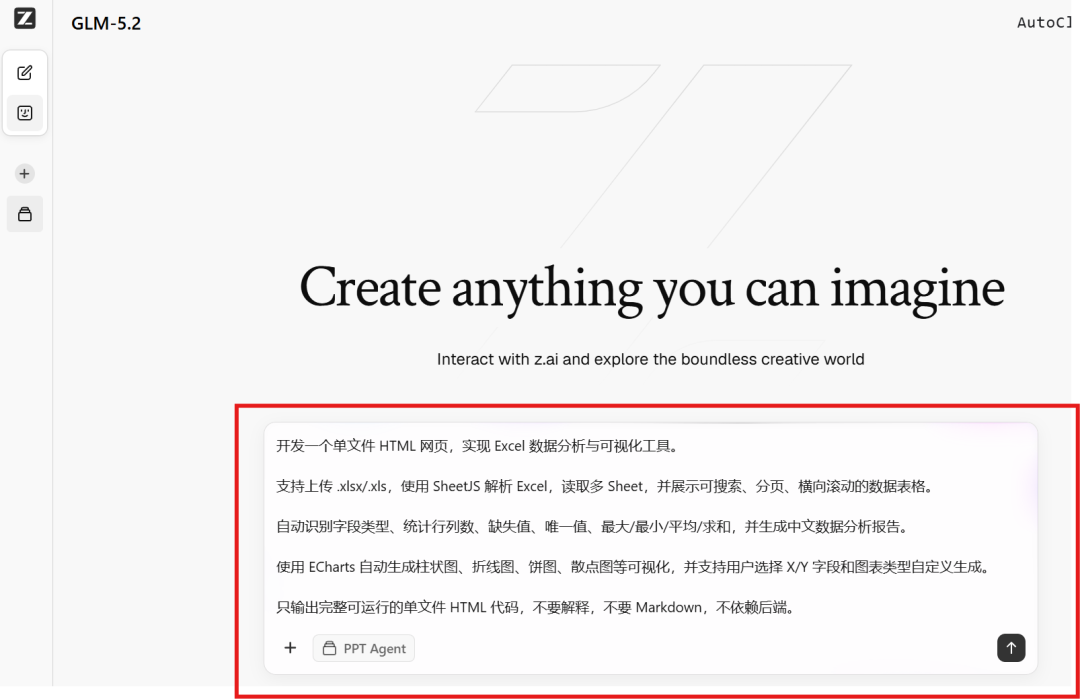
保存为html文件,并打开:

导入一个Excel文件,自动分页展示:
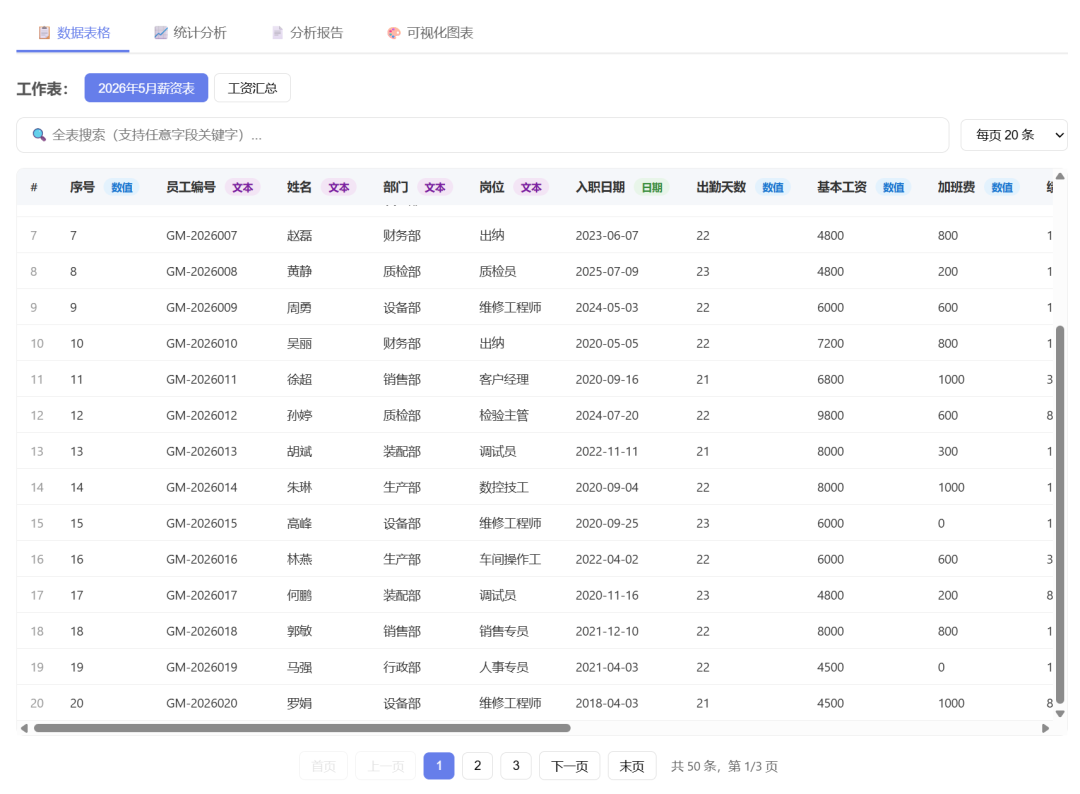
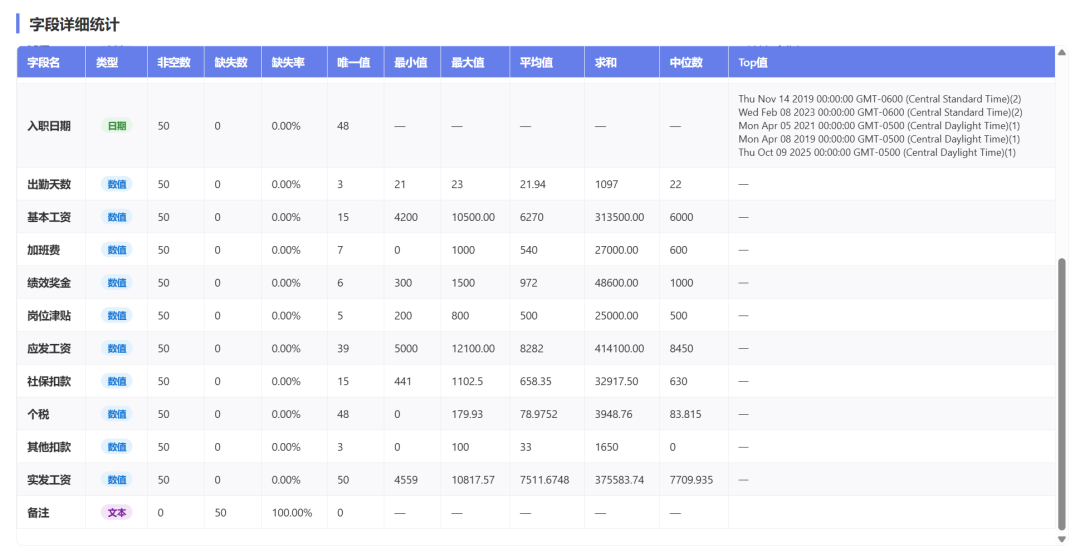
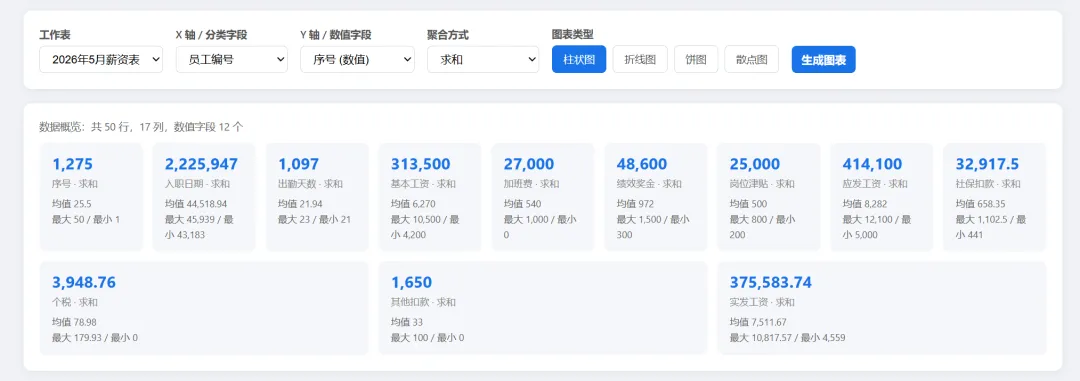
下面是数据统计预览:
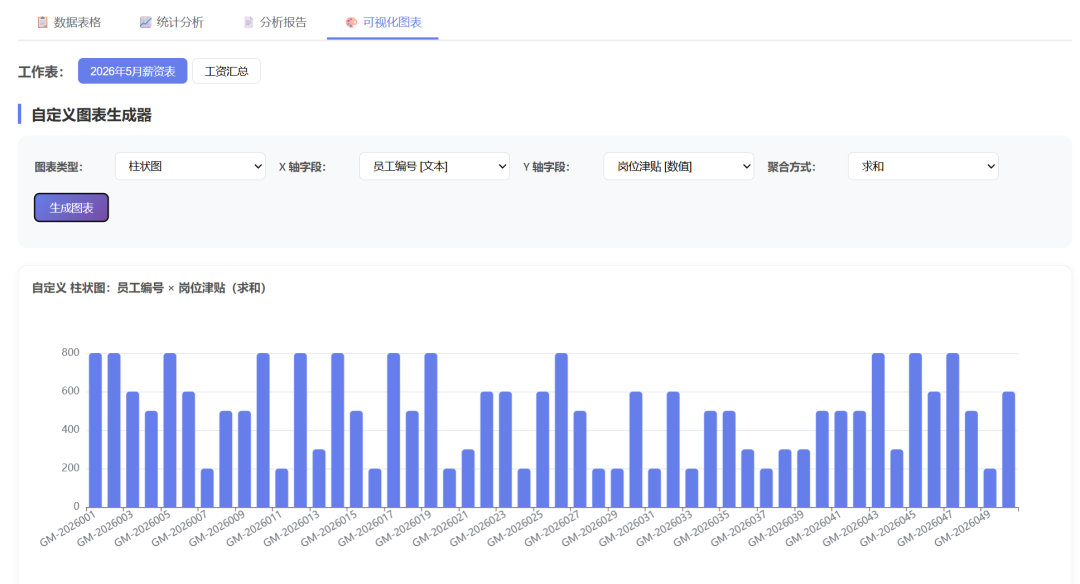
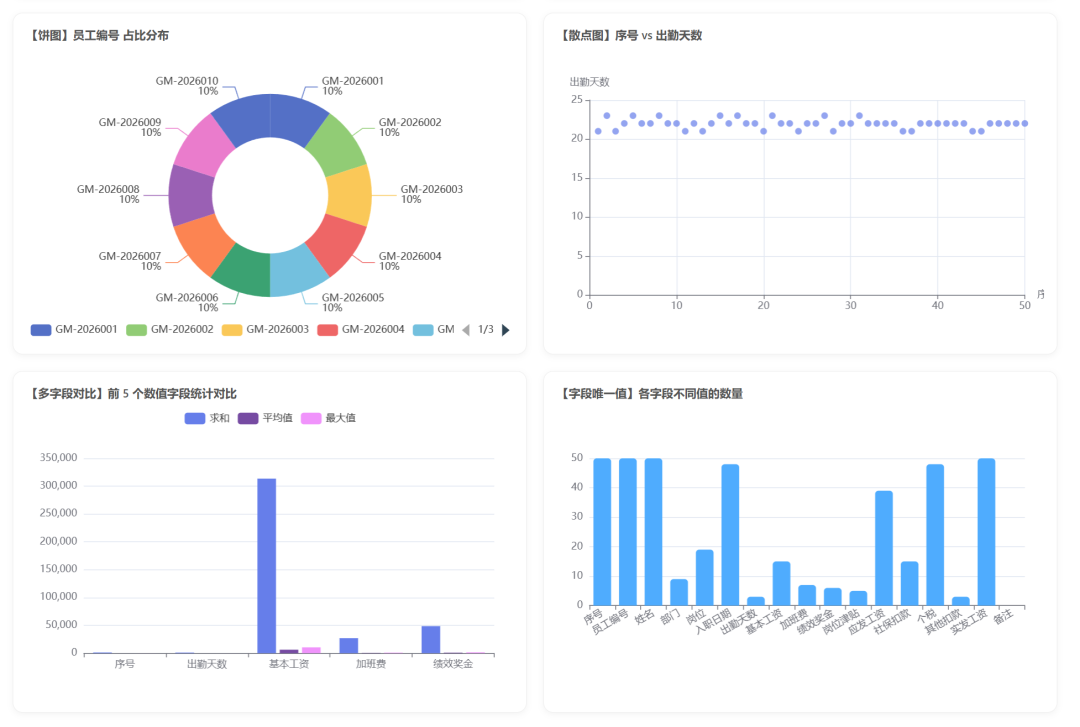
生成的部分图表:
同样任务发给 Opus 4.8 ,打开html文件:
数据预览:
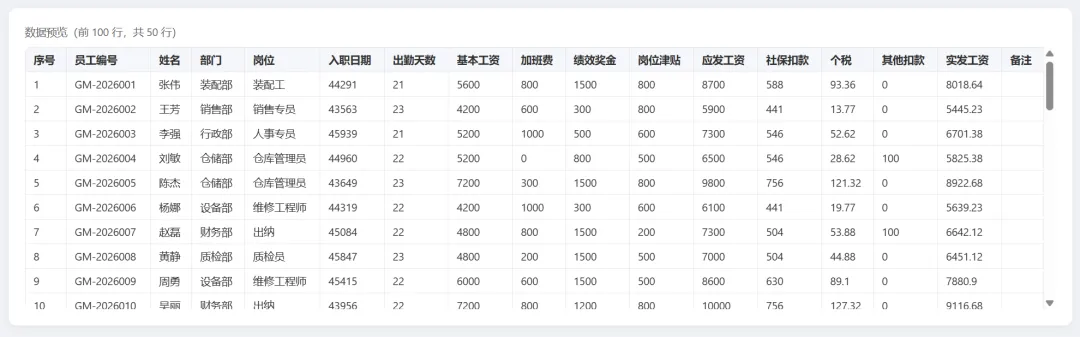
图表:
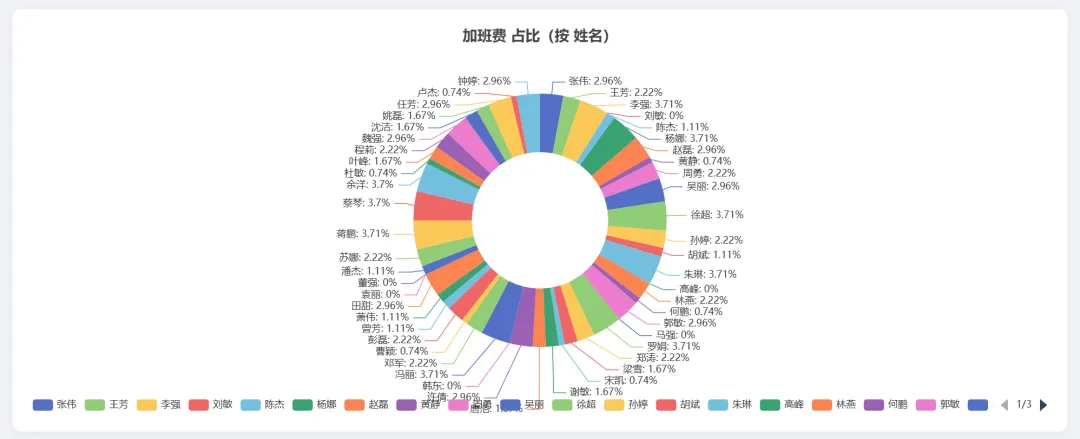
同样任务发给:Kimi 2.7 Code
但是Kimi官方,无最新这个模型:
我选择通过API调用它:
|
|
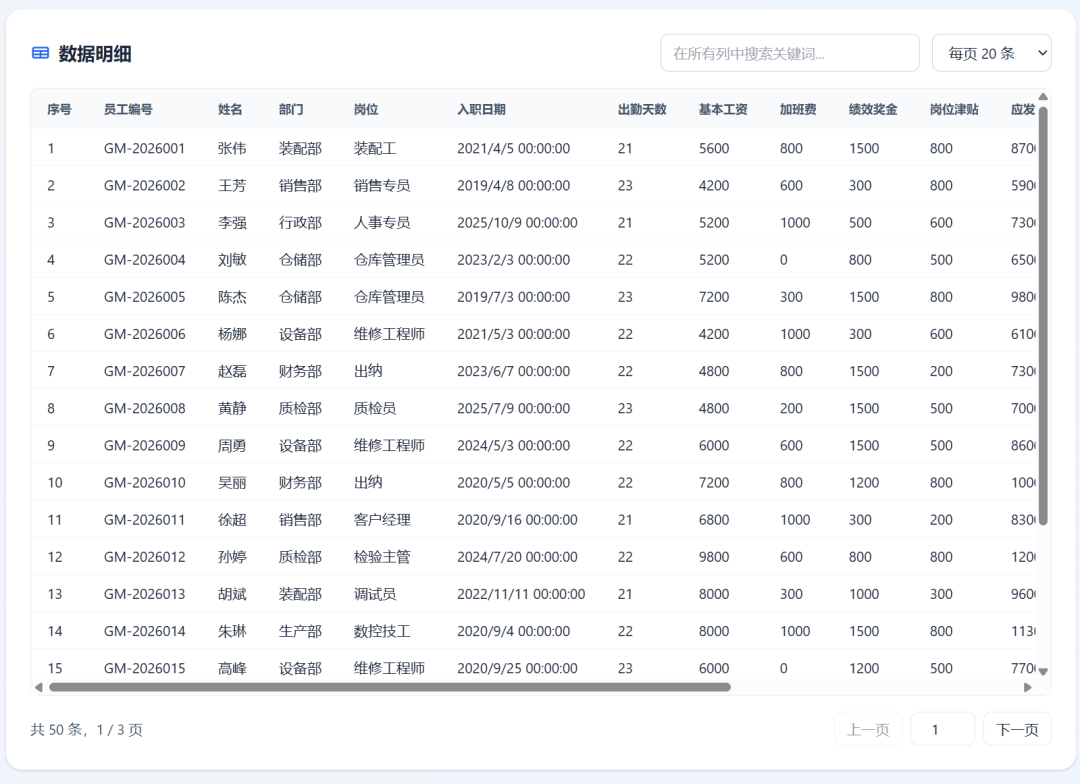
双击打开html,显示如下:
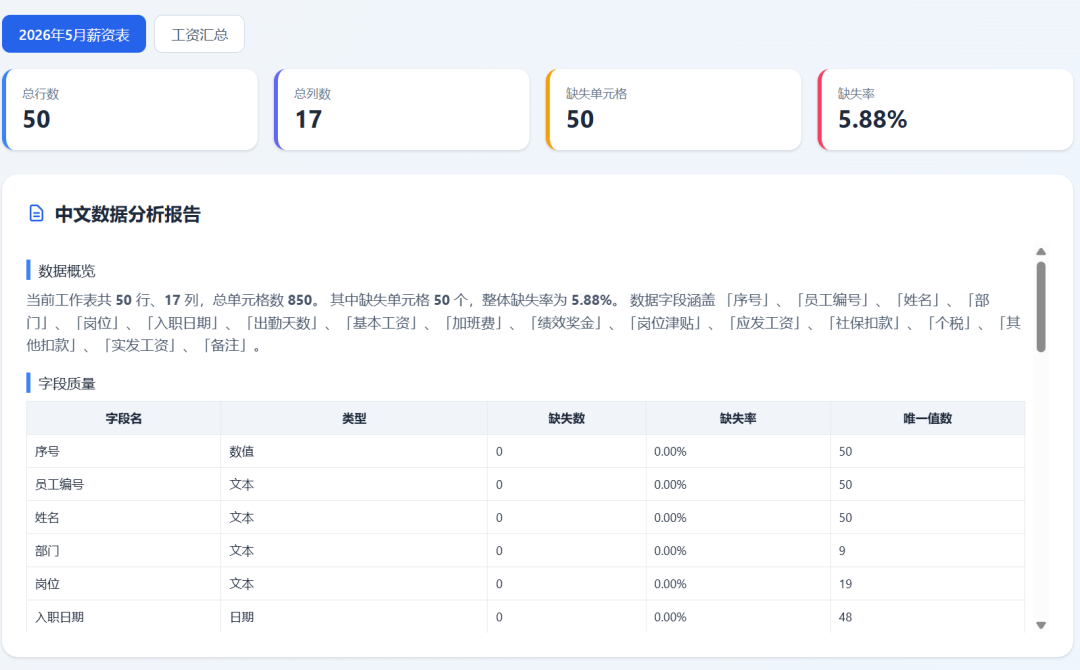
加载Excel后,数据预览,字段类型,统计:
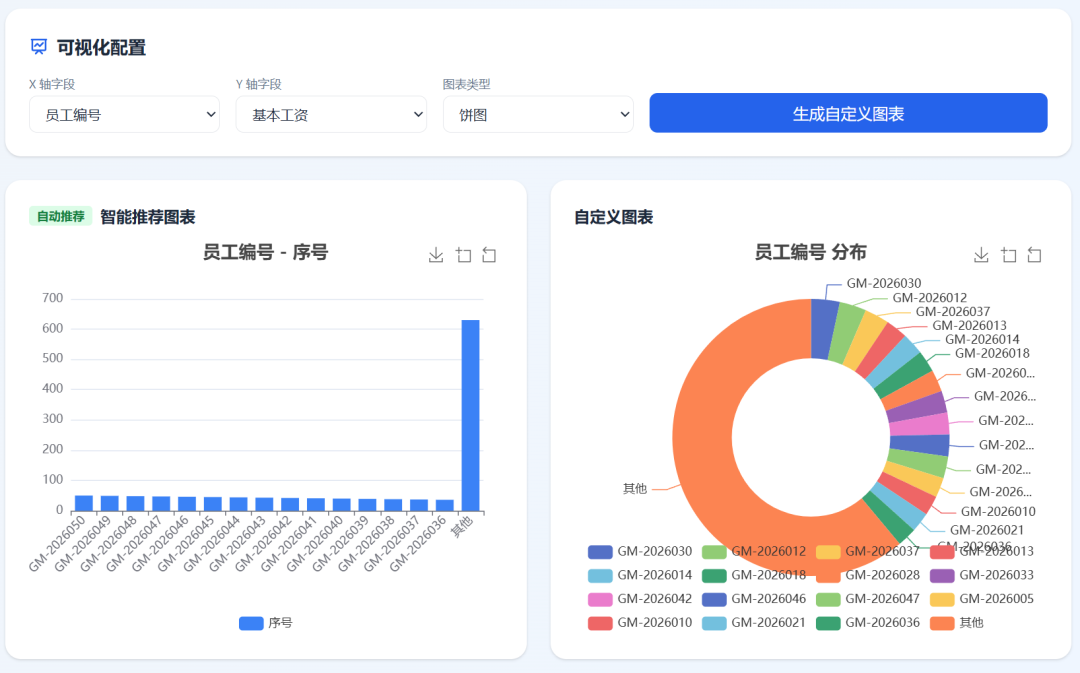
可视化图:
裁判打分
为了更加客观,交给裁判Gemini-3.1-Pro模型,评估如下图所示:
这是Gemini-3.1-Pro使用的三个打分维度:
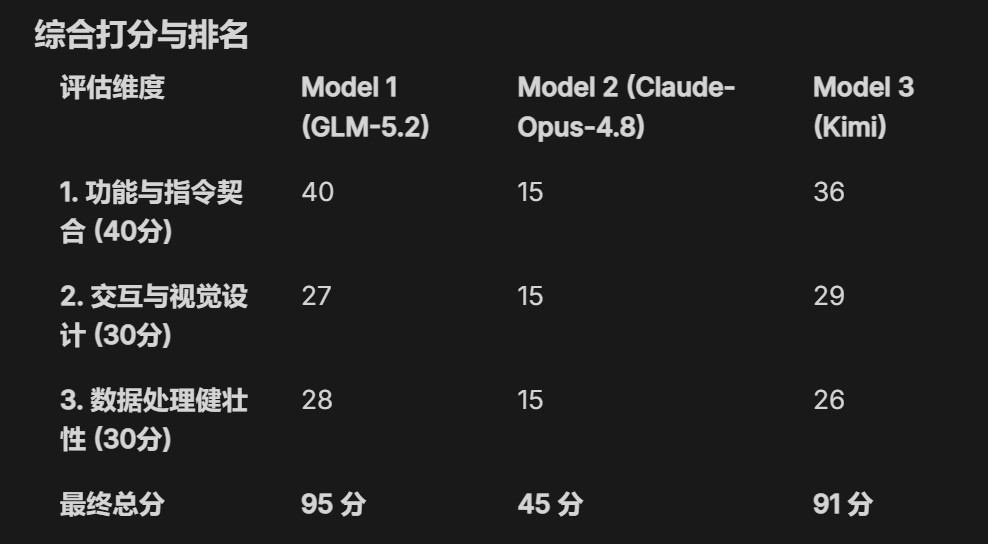
最终打分:

Claude Opus 4.8,竟然得分只有45,位于最后一名,
让我相当意外,因为按照文章开头的排名,Opus 4.8应该是第一才对!
这是为什么?再让裁判点评下:
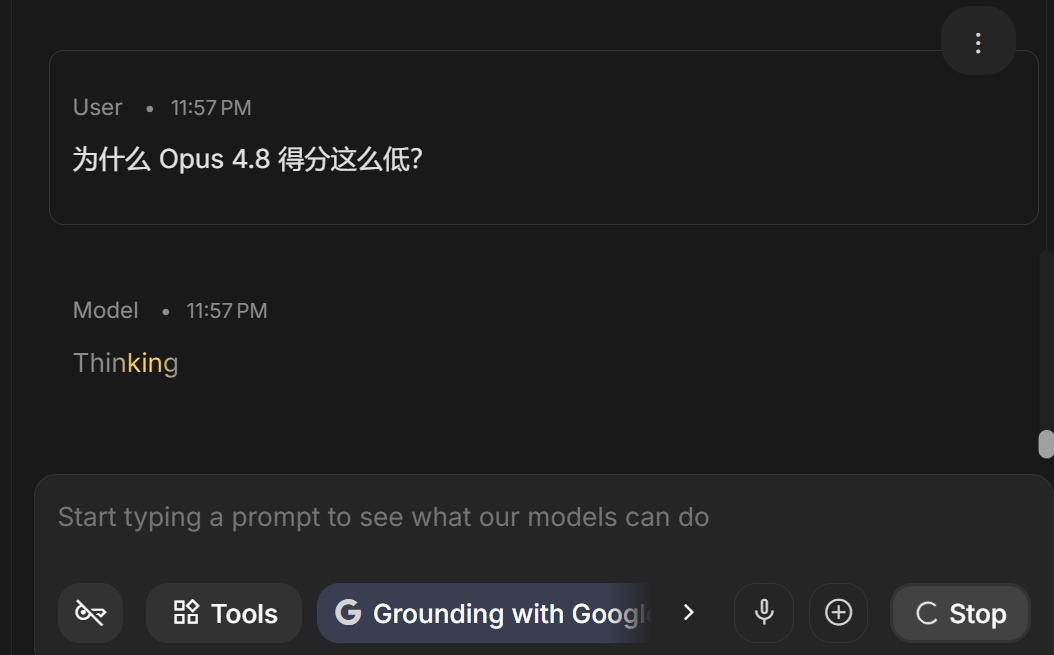
结论如下:
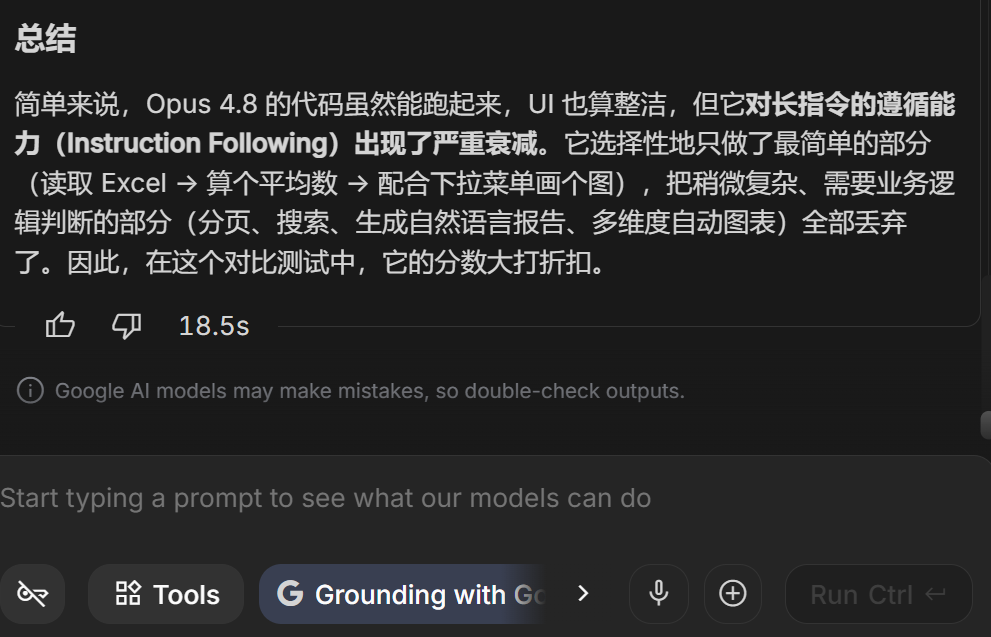
Opus 4.8 失败的根本原因在于出现了严重的指令遗漏,它完全忽略了搜索、分页、中文分析报告和自动图表推荐等核心要求,仅交付了一个功能残缺的基础半成品。
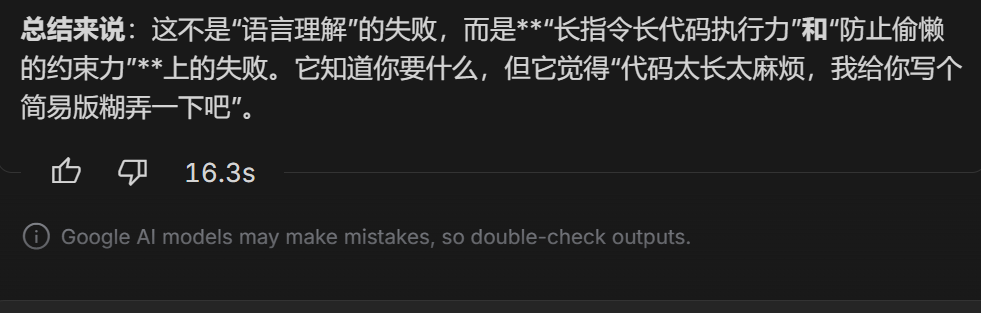
总结一下
在开发复杂单文件Excel数据分析应用的实测中,GLM-5.2 与 Kimi 2.7 Code 表现惊艳,双双逆袭超越了跑分公认霸主 Claude Opus 4.8 这一“离谱”反转的根源在于,本应最强的 Opus 4.8 触发了大模型的“代码惰性”,因注意力衰减严重遗漏了搜索、分页和分析报告等核心指令,最终垫底。此次评测深刻证明,在处理真实的长程工程任务时,模型对复杂长提示词的“指令服从度”和“抗偷懒能力”,远比单纯的理论跑分更加关键。